
Probably Wrong
Stochastic Contamination: The Case Against Probabilistic AI in Financial Data Processing

Author: Lucy Cohen

Abstract
The deployment of large language models and probabilistic AI systems in financial services is accelerating. Regulators are responding with governance frameworks that address transparency, explainability, and bias. None of the frameworks currently in force, including the EU AI Act, the Financial Conduct Authority’s guidance on AI in financial services, the Financial Reporting Council’s audit standards, the IAASB’s International Standards on Auditing, PCAOB oversight requirements, HMRC’s Making Tax Digital framework, or Companies House filing standards, prohibits the use of probabilistic AI in financial data processing on architectural grounds. This paper argues that they should, and provides the theoretical and empirical basis for that prohibition.
This paper introduces the concept of Stochastic Contamination: the irreversible introduction of probabilistic uncertainty into a data system whose integrity depends on deterministic verifiability. Financial data is not information in the general sense - it constitutes a system of constrained truth claims governed simultaneously by mathematical conservation laws, legal obligations of accuracy, and audit verifiability requirements. This paper formalises these properties as the Financial Epistemic Integrity condition and demonstrates that it is incompatible, at the architectural level, with the output properties of any probabilistic generative system.
This paper states and proves the Stochastic Contamination Theorem: that any probabilistic AI system operating on financial data introduces uncertainty that is undetectable at the point of introduction, unverifiable without complete re-derivation from source data, and therefore irrecoverable within any audit or compliance framework that does not itself have access to those source data in their entirety. The paper further demonstrates that the properties of transformer-based large language models, including token-level stochastic sampling, attention-weighted context compression, and the absence of a traceable logical derivation chain between input and output, produce contamination that cannot be corrected by retrieval augmentation, fine-tuning on financial corpora, or constitutional constraint mechanisms. The disqualification is architectural, not operational.
The paper draws on empirical evidence from a live deployment of a deterministic financial processing system across UK micro-businesses, in which contamination-free processing produced a defect rate of zero against materiality thresholds, while probabilistic-adjacent human-assisted processing introduced errors at rates consistent with documented manual processing failure rates. The argument extends to the systemic implications: contaminated financial data propagating into statutory audit, published financial statements, tax submissions to HMRC and Companies House, stock market valuations, credit ratings, and macroeconomic accounting. The paper proposes a minimum property set, the Financial AI Fitness Standard, that any AI system must satisfy before operating on financial data, and identifies the specific amendments required across each regulatory framework to encode this standard into law.
The financial system depends on the integrity of the data that describes it. Probabilistic AI systems are incapable of preserving that integrity by design. The question is not whether this matters - because it does; it is whether regulators will act before the contamination becomes systemic.
Keywords: stochastic contamination, financial epistemic integrity, large language models, probabilistic AI, financial data integrity, audit, deterministic verification, AI governance, FCA, FRC, IAASB, PCAOB, HMRC, Companies House
1. Introduction
In 2024, Bloomberg reported that major financial institutions, including Morgan Stanley, JPMorgan, and Goldman Sachs were deploying large language model applications for client-facing analysis, document processing, and financial summarisation. In 2025, the Big Four accounting firms collectively committed billions of dollars to AI integration across audit, tax, and advisory functions. HMRC announced the progressive automation of compliance checking through AI-assisted data matching. The momentum is institutional, the investment is substantial, and the direction is clear: probabilistic AI is moving into financial data processing at scale.
The governance response has not kept pace. The EU AI Act classifies AI systems by risk domain and mandates transparency, explainability, and human oversight. The Financial Conduct Authority has published guidance requiring firms to ensure AI outputs are explainable and subject to appropriate controls. The Financial Reporting Council has acknowledged AI’s growing role in audit while reaffirming the primacy of auditor judgement. The IAASB and PCAOB are consulting on how existing audit standards apply to AI-assisted procedures. HMRC and Companies House accept digitally processed submissions without architectural requirements on the systems that produced them. Across every framework, the question being asked is how probabilistic AI should be governed in financial contexts. This paper argues that the question is wrong. The question that should be asked is whether probabilistic AI is architecturally capable of operating on financial data without corrupting it.
The answer this paper provides, formally and empirically, is that it is not.
The argument turns on a distinction that the governance literature has not yet made with sufficient precision: the distinction between information in the general sense and financial data as a special epistemic category. Information, in the general sense, tolerates approximation. A language model that produces a plausible summary of a news article, a persuasive draft of a contract, or a reasonable answer to a factual question may be useful even when it is imprecise, because the cost of imprecision is bounded and correctable. Financial data does not share this tolerance. A financial record is not a representation of approximate economic reality. It is a constrained truth claim that must simultaneously satisfy a mathematical conservation law, a legal obligation of accuracy enforceable by regulatory sanction, and an audit verifiability requirement that demands every figure be traceable to its source. Approximation in financial data is not imprecision. It is contamination.
This paper introduces the concept of Stochastic Contamination to name this phenomenon precisely. Stochastic Contamination occurs when a probabilistic generative system introduces uncertainty into a financial data system at a point where that uncertainty cannot subsequently be detected, isolated, or removed without complete re-derivation of the affected records from source data. The contamination is not merely a risk of error, but a structural property of the interaction between probabilistic output generation and the verifiability requirements that financial data must satisfy. It occurs whether or not the probabilistic system produces a correct output in any given instance, because the absence of a deterministic derivation chain means that correctness cannot be established without reference to information the system does not possess and cannot provide.
This paper puts forward several arguments:
Section 2 establishes the epistemic category of financial data formally, defining the Financial Epistemic Integrity condition and distinguishing financial data from other information types on mathematical, legal, and audit grounds.
Section 3 introduces the Stochastic Contamination framework, defining the concept precisely, establishing its conditions of occurrence, and demonstrating why contamination, once introduced, is irrecoverable within standard audit and compliance architectures.
Section 4 states and proves the Stochastic Contamination Theorem, which formalises the incompatibility between probabilistic AI output properties and the Financial Epistemic Integrity condition.
Section 5 applies the theorem specifically to large language models, examining why the architectural properties of transformer-based systems produce contamination that retrieval augmentation, domain fine-tuning, and constitutional constraint cannot resolve.
Section 6 surveys the regulatory landscape across the FRC, FCA, IAASB, PCAOB, HMRC, and Companies House, identifying precisely where each framework’s conceptual vocabulary is insufficient to detect or prohibit contamination and what amendment would close each gap.
Section 7 extends the argument to the systemic level, examining the propagation of contaminated financial data into statutory audit, published financial statements, capital market valuations, credit assessments, and macroeconomic accounting. Section 8 presents empirical evidence from a live deterministic financial processing deployment as proof of concept for the alternative architecture. Section 9 proposes the Financial AI Fitness Standard: a minimum property set, derived directly from the theorem, that any AI system must satisfy before operating on financial data.
The conclusion asks three things of the reader. First, to accept the Financial Epistemic Integrity condition as a real and consequential property of financial data that current governance frameworks have failed to formalise. Second, to accept the Stochastic Contamination Theorem as a mathematical fact about the interaction between probabilistic AI and that condition, subject to the proof offered in Section 4. Third, to accept that the Financial AI Fitness Standard proposed in Section 9 represents not an aspirational policy preference but the minimum requirement for AI governance in financial contexts to be something other than fiction.
The financial system is built on the assumption that the data describing it is trustworthy. Probabilistic AI systems cannot satisfy that assumption by design. Every day that assumption goes unexamined while probabilistic systems process financial data is a day in which the trustworthiness of that data erodes in ways that are, by the theorem proved in this paper, undetectable until after the damage is done.
2. Financial Data as a Special Epistemic Category
The governance literature on AI in financial services treats financial data as a high-stakes instance of data in general. The concern is that errors in financial data have large consequences, not that financial data has properties that make certain classes of error structurally different from errors in other domains. This conflation is the root of the regulatory gap identified in Section 1. Financial data is not high-stakes general information. It is a categorically distinct epistemic object, and the distinction has direct implications for what kinds of system may legitimately produce or process it.
This section establishes that distinction formally. We define three properties that together constitute the Financial Epistemic Integrity condition, demonstrate that each property is independently necessary for financial data to function as financial data, and show that the conjunction of all three creates a requirement for deterministic verifiability that no probabilistic generative system can satisfy.
2.1 The Mathematical Conservation Property
Financial data is governed by a conservation law with no analogue in general information systems. The fundamental accounting equation, expressed in its most general form as:
ΔAssets = ΔLiabilities + ΔEquity
is not a convention or a rule of practice. It is a mathematical identity that must hold across every state of a financial system at every point in time. Every financial record, every transaction, every reported balance is a claim about the state of a system subject to this constraint. A financial record that violates the conservation law is not an inaccurate record; actually, it is not a financial record at all. It has failed the minimum condition for membership in the class of objects to which financial data belongs.
This conservation property has a deeper formal structure than the surface equation suggests. Each transaction admitted into a financial system must preserve the conservation constraint across the entire state of that system, not merely within the account or ledger directly affected. A transaction that produces a locally correct entry while creating a global imbalance has not produced a financial record. It has produced a defect. The implication is that financial data processing is not a collection of independent record-keeping acts. It is a state-preserving operation across a constrained system, and the constraint must hold continuously, not merely at the point of reporting. In short, financial systems must balance at all times – and that is the condition on which the entire global financial ecosystem is built.
The conservation property has a further implication that is directly relevant to the contamination argument. Because the constraint must hold globally, a local error, one that affects a single transaction or a single account balance, propagates through the system until it is detected and corrected. A misclassified transaction does not remain locally contained. It produces an incorrect account balance, which produces an incorrect trial balance, which produces incorrect financial statements, which produces incorrect tax submissions, which produces incorrect regulatory filings. The propagation is total. This property, which we term conservation propagation, means that the cost of a financial data error is not bounded by the magnitude of the error at its point of introduction. It is bounded only by the reach of the financial system into which it propagates.
2.2 The Legal Obligation Property
Financial data carries a legal obligation of accuracy that distinguishes it categorically from most other information types. In the United Kingdom, the Companies Act 2006 requires that financial statements give a true and fair view of the company’s financial position and performance. HMRC requires that tax returns accurately reflect the underlying financial records. Companies House requires that filed accounts represent the company’s actual financial state. These are legally enforceable obligations backed by criminal sanctions for deliberate falsification and civil penalties for negligent inaccuracy.
The legal obligation property creates an epistemic requirement that goes beyond accuracy in the ordinary sense. A financial record must be demonstrably correct, in the sense that its correctness can be established through reference to verifiable source evidence if challenged by a regulator, an auditor, or a court. A financial record whose correctness cannot be demonstrated is a legally deficient record, regardless of whether it happens to be numerically accurate.
This demonstrability requirement has a structural form that the conservation property alone does not capture. A financial record must be derivable from accessible source evidence through a process that can be re-run, inspected, and confirmed by a third party operating independently of the system that produced it. A record whose numerical content is correct but whose derivation from source cannot be demonstrated fails this requirement as completely as a record that is numerically wrong. The correctness of the number is not the point. The verifiability of its derivation is.
2.3 The Audit Verifiability Property
The third property of financial data follows from and extends the first two. Every figure in a financial system must be traceable, through an unbroken chain of derivation, to primary source evidence: bank statements, invoices, contracts, payroll records, asset valuations, and similar documents that exist independently of the financial data system itself. This traceability requirement, which we term the audit trail condition, is the operational expression of the legal obligation property and the enforcement mechanism of the conservation property.
The audit trail condition has both a backward-looking and a forward-looking dimension. Backward-looking traceability means that any figure in a financial statement can be decomposed into the transactions that produced it, and each transaction can be traced to the source document that evidenced it. Forward-looking traceability means that any source document can be followed through the processing chain to identify every financial record it affected and every balance it contributed to. Together, these two dimensions create what the International Standards on Auditing describe as a complete and auditable record, a data system in which every number has a provenance and every provenance is accessible (IAASB, 2023).
The audit verifiability property creates a structural requirement for financial data processing that is distinct from the conservation and legal obligation properties, though related to both. A financial data processing system must not merely produce outputs that satisfy the conservation law and comply with legal accuracy obligations. It must produce outputs whose derivation is transparent, step-by-step, and traceable to source. The derivation chain is part of the financial record itself, without which the record fails the audit verifiability property and cannot be admitted into the verified financial state.
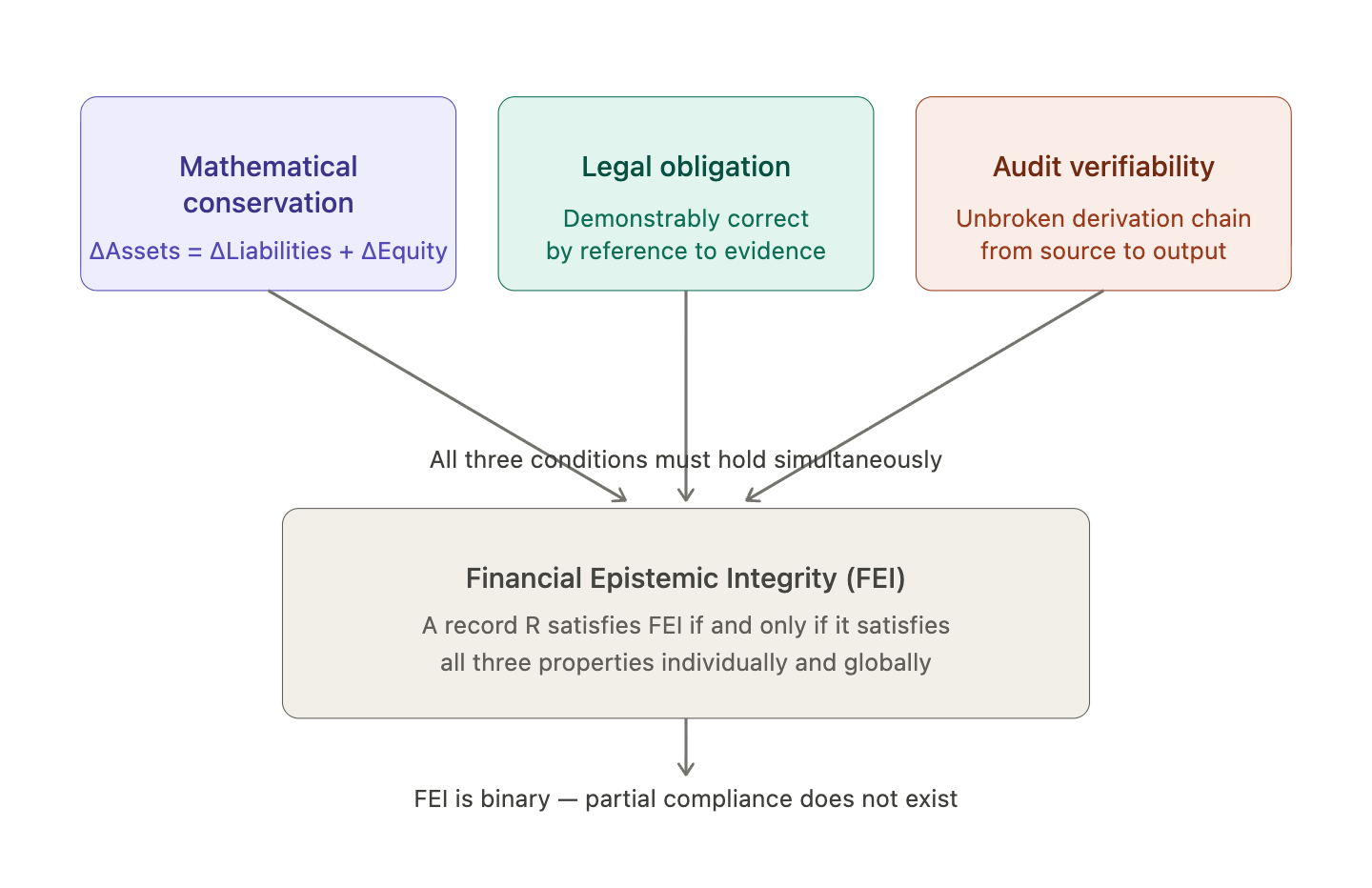
2.4 The Financial Epistemic Integrity Condition
The three properties established in Sections 2.1 through 2.3 jointly define what we term the Financial Epistemic Integrity condition. Formally:
A financial data record R satisfies Financial Epistemic Integrity (FEI) if and only if:
(i) R is consistent with the conservation constraint across the financial state system of which it forms part;
(ii) There exists a set of accessible and auditable source evidence E such that the correctness of R can be established by reference to E; and
(iii) The derivation of R from E is traceable through an unbroken, step-by-step chain that is itself auditable.
A financial data system satisfies FEI if, and only if, every record within it satisfies FEI individually, and the conservation constraint holds globally across all records jointly.
The Financial Epistemic Integrity condition is not a new regulatory standard per se, although labelling it as such in this paper is useful for its application in the future. It is a formalisation of what financial data has always been required to be, expressed in terms precise enough to evaluate whether a given processing system is capable of producing records that satisfy it. The value of the formalisation lies precisely in this evaluative function. Once FEI is stated precisely, it becomes possible to ask, rigorously, whether any given class of AI system is architecturally capable of satisfying it. Section 3 and Section 4 address that question directly.
Two observations about the FEI condition are worth making before proceeding. First, FEI is a binary property, not a matter of degree. A record either satisfies all three conditions or it does not. There is no partial FEI, no approximately compliant financial record, no acceptable level of contamination. This follows directly from the conservation law: a financial state that partially satisfies the conservation constraint is not a financial state - it is a defective data structure. Second, FEI applies to the processing system, not merely to the output. A financial record that happens to be numerically correct but whose derivation is not traceable fails FEI regardless of its accuracy, because the audit verifiability property is violated. This point is of fundamental importance for the argument that follows: the question is not whether a probabilistic AI system sometimes produces correct financial outputs. It is whether the system’s architecture is capable of producing outputs that satisfy all three FEI conditions simultaneously. Section 4 proves that it is not.
3. The Stochastic Contamination Framework
The term contamination is chosen deliberately. In chemistry and biology, contamination describes the introduction of a foreign substance into a system in a way that alters the system’s properties and cannot be reversed by removing the contaminant after the fact, because the contaminant has already interacted with and changed the host system. Financial data contamination works by an analogous mechanism. Once probabilistic uncertainty is introduced into a financial data system at a point where it cannot be detected, the downstream records derived from that point carry the uncertainty forward, and removing it requires not merely correcting the contaminated record but re-deriving every subsequent record that depended on it from source. In a financial system of any complexity, this is equivalent to reconstructing the entire financial history from primary documents. The contamination is not a stain that can be wiped away in the same way that you cannot return a cake to it’s source ingredients. It is a structural alteration that propagates through the system’s conserved state.
This section defines Stochastic Contamination precisely, establishes its conditions of occurrence, identifies its distinguishing properties, and demonstrates why it is irrecoverable within standard audit and compliance architectures. The formal proof of its incompatibility with probabilistic AI systems is reserved for Section 4.
3.1 Definition of Stochastic Contamination
Stochastic Contamination is defined as follows:
A financial data system S is stochastically contaminated at time t if there exists at least one record R admitted into S at or before time t such that:
(i) R was produced by a process that does not preserve a deterministic, traceable derivation chain from primary source evidence to output; and
(ii) The probabilistic uncertainty introduced by that process is not represented within R or within the audit trail of S in a form that permits its identification, quantification, or isolation.
Several features of this definition require explicit commentary.
First, the definition does not require that R be numerically incorrect. A record produced by a probabilistic process may happen to contain the correct figures. The contamination occurs regardless, because the audit verifiability property of FEI requires not merely correct outputs but traceable derivations. A correct output without a traceable derivation is a contaminated record in the sense defined here, because its correctness cannot be established by audit without independent re-derivation from source.
Second, the definition requires that the uncertainty be unrepresented in the audit trail. This condition distinguishes Stochastic Contamination from ordinary uncertainty, which financial systems handle through provisions, estimates, and disclosures. A provision for doubtful debts introduces uncertainty into a financial system, but that uncertainty is explicitly quantified, disclosed, and subject to audit scrutiny. Stochastic Contamination is uncertainty that enters the system invisibly, without disclosure, and without any mechanism within the standard audit architecture for its detection.
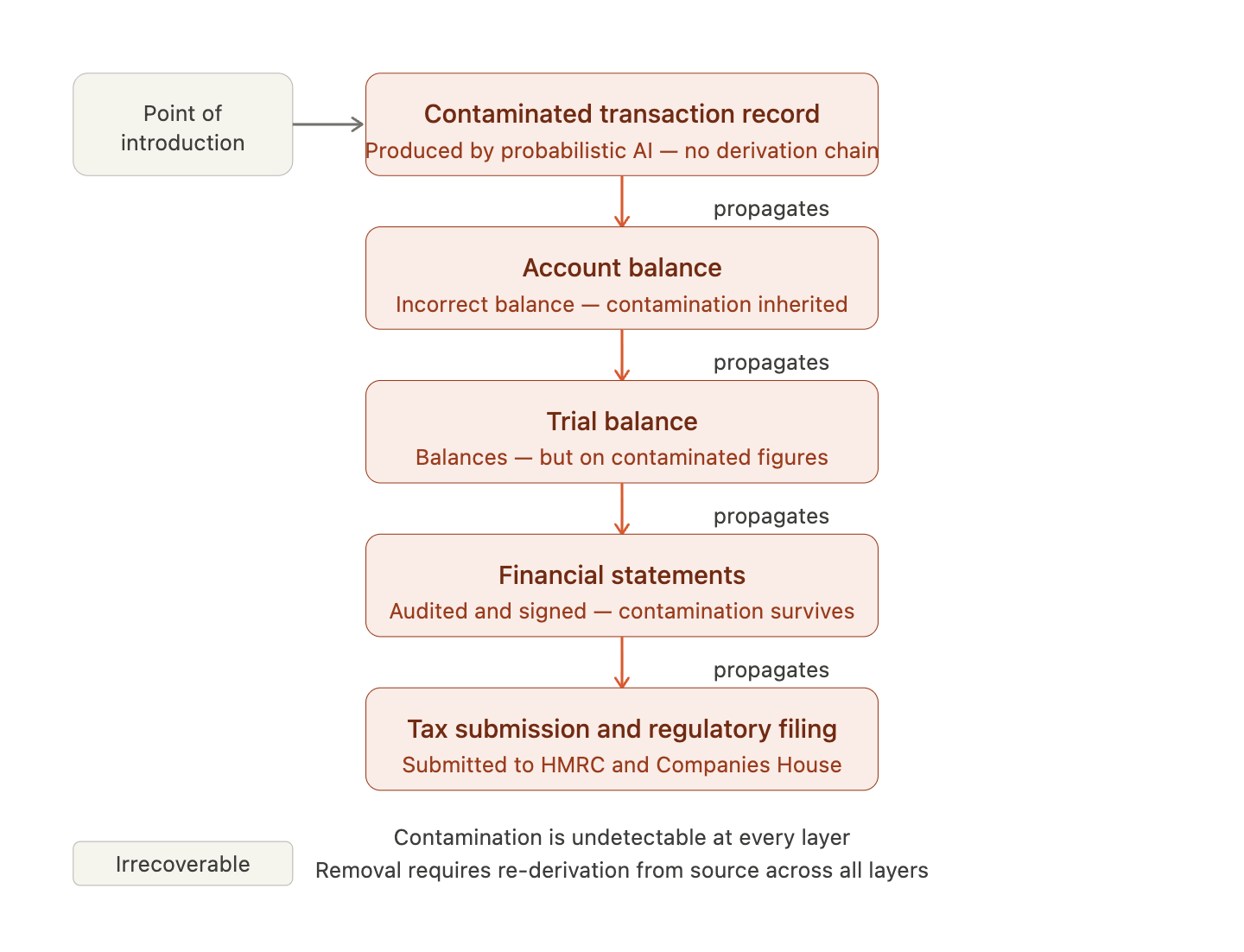
Third, the definition is cumulative. Once a contaminated record is admitted into a financial system, every subsequent record derived from it inherits the contamination. Because the conservation property requires global consistency across the financial state, a contaminated record does not remain locally isolated. It affects every balance, every report, and every submission that draws on the financial state of which it forms part. Contamination at the transaction level propagates to account level, to trial balance level, to financial statement level, to regulatory submission level, in a chain that is as deterministic as the conservation law itself.
3.2 Conditions of Occurrence
Stochastic Contamination occurs when three conditions are jointly satisfied.
The first condition is probabilistic output generation. The processing system produces its output through a mechanism that involves stochastic elements, meaning that the output is a function of a probability distribution over possible outputs rather than a deterministic function of the input. This condition is satisfied by any system whose output cannot be fully predicted from its inputs without knowledge of the random seed or sampling process used during generation.
The second condition is absence of derivation traceability. The processing system does not produce, as a byproduct of its output generation, a step-by-step record of how the output was derived from the input. This condition is satisfied whenever the mapping from input to output involves intermediate computational states that are not stored, not auditable, and not recoverable after the fact.
The third condition is admission into the financial state. The output of the probabilistic system is admitted into the financial data system as a financial record, meaning that it becomes part of the accepted financial state against which balances are calculated, reports are produced, and regulatory submissions are made.
When all three conditions are jointly satisfied, Stochastic Contamination occurs. The conditions are jointly necessary: a probabilistic system that does not produce outputs admitted into the financial state does not contaminate it, and a system that produces outputs admitted into the financial state but does so through a deterministic and traceable process does not produce contamination in the sense defined here. The contamination is a product of the specific combination of probabilistic generation and financial state admission without derivation traceability.
3.3 The Undetectability Property
The most consequential feature of Stochastic Contamination, and the feature that distinguishes it from ordinary financial error, is its undetectability within standard audit and compliance architectures. This property requires careful elaboration because it is counterintuitive: if a record is wrong, why cannot an auditor detect the error?
The answer is that audit, as currently practised under International Standards on Auditing and equivalent national frameworks, is a sampling and evidence-based procedure, not an exhaustive verification. Auditors do not verify every financial record independently from source. They assess risk, select samples, examine evidence for selected items, and form a judgment about the overall reliability of the financial statements. This approach is rational given the volume of transactions in any significant financial entity and the cost of exhaustive verification. It works because the errors it is designed to catch, human processing errors, misclassifications, omissions, duplicate entries, have detectable signatures. They produce inconsistencies with source documents, violations of the conservation constraint, implausible patterns in account balances, or anomalies that risk assessment procedures are designed to identify.
Stochastic Contamination does not have these signatures. A contaminated record produced by a probabilistic AI system may be fully consistent with the conservation constraint, because the system may have correctly maintained the accounting equation while misclassifying the nature of a transaction. It may be consistent with the source document presented to the auditor, because the system may have processed the document but assigned it to an incorrect category in a way that is not apparent from the document itself. It may produce no anomalies in account balance patterns, because the misclassification may be systematic rather than random, producing internally consistent but incorrect accounts. It will not produce an audit trail inconsistency, because the probabilistic system does not produce an audit trail at all in the sense required by FEI. There is nothing for the auditor’s standard procedures to catch.
It is important to understand that the undetectability of Stochastic Contamination is not a temporary limitation of current audit technology. It is a structural consequence of the mismatch between how probabilistic systems generate outputs and what audit procedures are designed to detect. Audit procedures detect deviations from expected patterns in human-produced financial data. Probabilistic AI systems produce outputs that are specifically optimised to be plausible and pattern-consistent, because that is what their training process rewards. The more capable the probabilistic AI system, the more plausible its contaminated outputs, and therefore the less detectable the contamination.
3.4 The Irrecoverability Property
The second distinguishing feature of Stochastic Contamination is its irrecoverability within standard financial and audit architectures. Once a contaminated record has been admitted into the financial state and downstream records have been derived from it, removing the contamination requires identifying the contaminated record, which the undetectability property establishes cannot be done through standard audit procedures, and re-deriving every subsequent record that depended on it from source, which requires access to primary source documents and the processing capacity to reconstruct the financial history.
In practice, irrecoverability means that a financial system that has admitted contaminated records is in a state where the boundary between its reliable and unreliable records cannot be established without exhaustive re-verification from source. Importantly, this is not a proportionate or scalable response to a routine processing error, but the financial equivalent of a database corruption event, requiring full reconstruction rather than targeted correction. For a financial entity of any significant size, this is operationally equivalent to irreversibility.
The irrecoverability property has a temporal dimension that amplifies its consequences. Financial records do not exist in isolation. They are the basis for subsequent transactions, for period-end reporting, for tax submissions, for loan covenant calculations, for audit sign-off, and for the published financial statements on which investors, creditors, employees, and counterparties rely. Each of these downstream uses creates a new layer of records and decisions derived from the contaminated financial state. As time passes, the contamination does not becomes less detectable and more deeply embedded in the financial history of the entity and in the decisions of the parties who relied on that history. The irrecoverability of the original contamination compounds with every subsequent use of the contaminated financial state.
3.5 Stochastic Contamination and the FEI Condition
The relationship between Stochastic Contamination and the Financial Epistemic Integrity condition established in Section 2 is direct and formal. Stochastic Contamination violates FEI at the level of each of the three properties.
It violates the mathematical conservation property not necessarily by breaking the accounting equation in any individual record, but by breaking the global guarantee that the conservation constraint is satisfied across all records simultaneously. A financial state that contains contaminated records is one in which the satisfaction of the conservation constraint cannot be established without exhaustive verification, because some records in the system were produced by a process that does not guarantee conservation preservation by construction.
It violates the legal obligation property by producing records whose demonstrable correctness cannot be established, because there is no traceable derivation from source evidence that an auditor, regulator, or court can inspect and confirm. A contaminated record may be numerically correct, but it is legally deficient in the sense established in Section 2.2, because its correctness is asserted rather than demonstrated.
It violates the audit verifiability property directly and completely, because the audit trail condition requires an unbroken, step-by-step derivation chain from source to output, and probabilistic generative systems do not produce such chains. The contamination is not a gap in the audit trail. It is the complete absence of the audit trail at the point of the contaminated record, with consequences for every downstream record derived from it.
The formal proof that probabilistic AI systems necessarily produce Stochastic Contamination when operating on financial data, and therefore necessarily violate FEI, is the subject of Section 4.
4. The Stochastic Contamination Theorem
This section states and proves the central formal claim of this paper: that any probabilistic AI system operating on financial data necessarily produces Stochastic Contamination as defined in Section 3, and therefore necessarily violates the Financial Epistemic Integrity condition established in Section 2. The proof is constructive, proceeding from the architectural properties of probabilistic AI systems through the three conditions of Stochastic Contamination to the violation of each FEI property in turn.
4.1 Preliminary Definitions
Let F be a financial data system satisfying the Financial Epistemic Integrity condition as defined in Section 2.4. Let A be a probabilistic AI system with the following properties:
P1 (Stochastic output generation): The output of A is a function of a probability distribution over possible outputs. Formally, for any input x, A produces output y drawn from a conditional probability distribution P(y | x; θ), where θ represents the parameters of A. The output y is not a deterministic function of x: for identical inputs x, A may produce different outputs y across runs.
P2 (Absence of derivation traceability): A does not produce, as a component of its output, a step-by-step derivation chain mapping x to y through auditable intermediate states. The mapping from x to y involves intermediate computational states that are neither stored nor recoverable after the output y is generated.
P3 (Finite output vocabulary): A generates its output by sampling from a distribution over a finite vocabulary V of tokens, composing output y as a sequence y = (v₁, v₂, ..., vₙ) where each vᵢ ∈ V is drawn sequentially from P(vᵢ | v₁, ..., vᵢ₋₁, x; θ).
Properties P1 through P3 are satisfied by all transformer-based large language models as a consequence of their architecture (Vaswani et al., 2017). They are also satisfied by a broader class of probabilistic generative systems including diffusion models, variational autoencoders, and stochastic neural networks. The theorem is stated for probabilistic AI systems generally and applied specifically to transformer-based large language models in Section 5.
Let R_A denote a financial record produced by A operating on financial input data, and let S_A denote the financial data system that results from admitting R_A into F.
4.2 The Stochastic Contamination Theorem
Theorem (Stochastic Contamination): Let F be a financial data system satisfying FEI and let A be a probabilistic AI system satisfying properties P1, P2, and P3. If A operates on financial data drawn from F and produces output that is admitted into F as a financial record R_A, then S_A is stochastically contaminated in the sense of Definition 3.1, and S_A does not satisfy FEI.
Proof:
The proof proceeds in three parts, corresponding to the three conditions of Stochastic Contamination in Definition 3.1 and the three properties of FEI in Section 2.4.
Part I: R_A was produced by a process that does not preserve a deterministic, traceable derivation chain (Contamination Condition i).
By property P1, A produces its output y by sampling from the conditional distribution P(y | x; θ). The output y is therefore a realisation of a random variable, not a deterministic function of x. This means there exists no function g such that y = g(x) for all inputs x; rather, y ~ P(y | x; θ), meaning different outputs may be produced from identical inputs depending on the random seed employed at sampling time.
By property P3, A produces y sequentially, where each token vᵢ is drawn from P(vᵢ | v₁, ..., vᵢ₋₁, x; θ). The probability assigned to each token at each position is a function of the entire preceding context and the model parameters θ, but the specific token selected is determined by a sampling process that introduces stochasticity. Even in the limiting case of deterministic decoding, where argmax selection is used rather than stochastic sampling, the output is still a function of learned parameters θ rather than a deterministic logical derivation from input data, and therefore fails the derivation traceability requirement of FEI condition (iii). It is worth noting that the case of deterministic decoding, where argmax selection is used rather than stochastic sampling, does not escape this conclusion. Under argmax decoding P1 is technically weakened: the output becomes a deterministic function of the input given fixed parameters θ. However, the proof of Contamination Condition (i) does not depend on P1 alone. Even where output generation is deterministic, P2 is independently sufficient: the absence of an auditable intermediate state record mapping x to y means that no traceable derivation chain exists regardless of whether the output generation process is stochastic or deterministic. The argmax case therefore satisfies Contamination Condition (i) through P2 alone, and the stochasticity established by P1 and P3 is not necessary for this conclusion, though it strengthens it in the general case.
By property P2, A does not produce an auditable intermediate state record mapping x to y. The intermediate computational states through which A passes in generating y, specifically the attention weight matrices, the key-value computations across transformer layers, and the probability distributions over the vocabulary at each generation step, are transient and are not preserved in the output R_A or in any associated record that would constitute an audit trail in the sense required by the audit verifiability property of FEI.
Therefore, R_A was produced by a process that does not preserve a deterministic, traceable derivation chain from primary source evidence to output. Contamination Condition (i) is satisfied. A further clarification is required to connect the absence of a logical derivation function to the absence of a traceable chain from primary source evidence, as required by Contamination Condition (i). A traceable derivation chain from primary source evidence requires that every step of the derivation can be independently verified against that evidence by a third party without access to the system that produced the output. A statistical function mapping input tokens to a probability distribution over output tokens, and selecting the output by sampling from that distribution, cannot satisfy this requirement: its intermediate states are parameterised by θ, which encodes patterns learned from training data rather than logical rules applied to the specific source evidence presented at inference time. The derivation of R_A from source evidence E is therefore untraceable not merely because P2 establishes that intermediate states are not preserved, but because even if those states were preserved, they would not constitute a chain connecting E to R_A through logical steps that can be independently verified against E. The statistical function and the source-evidence derivation chain are categorically distinct objects.
Part II: The probabilistic uncertainty introduced by A is not represented within R_A or within the audit trail of S_A in a form that permits its identification, quantification, or isolation (Contamination Condition ii).
The output R_A produced by A takes the form of a financial record: a transaction classification, an account posting, a balance figure, or similar. Financial records of these types do not carry probability distributions as part of their structure. A financial record states that a transaction is classified as expense category C, or that account balance B has value V. It does not and cannot, within the structure of a financial record as defined by accounting standards and regulatory requirements, state that the classification has probability p₁ of being correct and probability 1-p₁ of being incorrect.
This is not a contingent limitation of current accounting software. It is a structural property of financial records as legal documents. A filed tax return, a Companies House filing, a balance sheet submitted under the Companies Act 2006, or a record produced for HMRC under Making Tax Digital cannot contain probability distributions over possible correct values. The legal framework requires that these documents assert specific figures as accurate representations of the financial state. A document that asserted a figure as probably correct would fail the legal obligation property of FEI and would not constitute a valid financial record.
Consequently, the probabilistic uncertainty inherent in R_A by virtue of P1, the fact that A’s output is a sample from a distribution rather than a deterministic derivation, is necessarily stripped from R_A at the point of its admission into F. The uncertainty is present in A’s generation process but absent from the record that enters the financial data system. Nothing in the audit trail of S_A represents this uncertainty, because the audit trail records only the admitted financial records and their derivation chains, and R_A carries no derivation chain that would permit the uncertainty to be reconstructed.
Therefore, the probabilistic uncertainty introduced by A is unrepresented in R_A and in the audit trail of S_A. Contamination Condition (ii) is satisfied.
Part III: S_A does not satisfy FEI.
Since both conditions of Stochastic Contamination are satisfied, S_A is stochastically contaminated by Definition 3.1. It remains to show that S_A does not satisfy FEI. This follows directly from the three FEI properties.
FEI property (i), the mathematical conservation property, requires that all records in S_A are consistent with the conservation constraint. Since R_A was produced by a process that does not guarantee conservation preservation by construction, the conservation constraint cannot be established to hold across S_A without exhaustive independent re-verification of R_A from source data. The conservation property of S_A is therefore unestablished, which is distinct from established and is sufficient to constitute a violation of FEI property (i). This conclusion requires one further clarification. A reviewer might observe that a probabilistic system could happen to produce outputs that preserve conservation even without architectural guarantees, and ask whether this constitutes satisfaction of FEI property (i) in practice. It does not, for the reason established in Section 2.1: FEI property (i) requires conservation by architectural construction, meaning the system must be designed such that no non-conserving output can enter the accepted financial state. Conservation by coincidence, where the system produces a conserving output in a given instance without any architectural mechanism preventing non-conserving outputs in other instances, does not satisfy the property. The FEI condition requires a guarantee, not an outcome. A probabilistic system that happens to produce conserving outputs on some or all runs provides no such guarantee, because its architecture permits non-conserving outputs and the occurrence of a conserving output in any given run does not establish that conservation will hold across the system as a whole.
FEI property (ii), the legal obligation property, requires that there exists a set of accessible and auditable source evidence E such that the correctness of R_A can be established by reference to E. By Part I, R_A was produced by a stochastic sampling process rather than a deterministic derivation from E. Therefore, reference to E alone cannot establish the correctness of R_A: even if E is consistent with R_A, an auditor examining E cannot determine whether A would always produce R_A from E, since by P1 A may produce different outputs from identical inputs. The demonstrability requirement of the legal obligation property is therefore violated.
FEI property (iii), the audit verifiability property, requires that the derivation of R_A from source evidence is traceable through an unbroken, step-by-step chain that is itself auditable. By Part I and Part II, no such chain exists for R_A: the derivation involves stochastic intermediate states that are not recorded and cannot be reconstructed. The audit trail condition is therefore violated directly and completely.
Since R_A violates all three FEI properties, S_A does not satisfy FEI. By the conservation propagation property established in Section 2.1, the violation propagates to every record in S_A that is derived from or affected by R_A.
4.3 Corollaries
Three corollaries follow directly from the theorem.
Corollary 1 (Independence from numerical accuracy): Stochastic Contamination of S_A occurs regardless of whether R_A is numerically correct. The theorem does not require that A produce an incorrect output. It requires only that A’s output be produced by a process satisfying P1, P2, and P3. A numerically correct output produced by such a process is still a contaminated record because it violates FEI properties (ii) and (iii) independently of its numerical content.
Corollary 2 (Independence from system capability): Stochastic Contamination occurs regardless of the capability or accuracy of A. A more capable probabilistic AI system, one with lower average error rates, higher factual accuracy, or better domain calibration, does not reduce the contamination it introduces into F. The contamination is a property of the interaction between the architectural properties P1, P2, and P3 and the FEI requirements, not of the system’s performance on accuracy benchmarks.
Corollary 3 (Irrecoverability): Once S_A is stochastically contaminated, the contamination cannot be removed without identifying all contaminated records, which requires exhaustive re-verification from source, and re-deriving every subsequent record that depended on them, which requires reconstructing the financial history. In a financial system of any practical complexity, this is operationally equivalent to irreversibility.
4.4 Scope of the Theorem
The theorem applies to all probabilistic AI systems satisfying P1, P2, and P3, and therefore applies to large language models, diffusion-based financial document processors, stochastic neural classifiers, and any other system whose outputs are samples from a learned probability distribution rather than deterministic derivations from input data. The theorem does not apply to fully deterministic rule-based systems whose outputs are logical functions of structured input data and whose derivation chains are fully auditable. The governance implication is therefore not that AI must be excluded from financial data processing. It is that only AI systems that do not satisfy P1, P2, and P3, that is, systems that are fully deterministic, fully traceable, and free of stochastic output generation, are architecturally compatible with the Financial Epistemic Integrity condition.
Section 5 applies this result specifically to large language models, examining why the architectural properties of transformer-based systems satisfy P1, P2, and P3 by construction and why proposed mitigations, retrieval augmented generation, domain fine-tuning, and constitutional constraints, do not alter this conclusion.
5. Why Large Language Models Are Architecturally Disqualified
The Stochastic Contamination Theorem proved in Section 4 applies to all probabilistic AI systems satisfying properties P1, P2, and P3. This section applies the theorem specifically to transformer-based large language models, which are the class of probabilistic AI system most actively being deployed in financial services contexts. The section proceeds in four parts: first, demonstrating that LLMs satisfy P1, P2, and P3 by architectural necessity; second, examining the three principal mitigation strategies proposed by the industry and demonstrating why none of them resolves the contamination problem; third, addressing the argument that sufficiently capable LLMs might achieve effective determinism through high accuracy; and fourth, establishing why the disqualification is permanent under the transformer architecture rather than a limitation of current model capability.
5.1 How LLMs Satisfy the Contamination Conditions by Construction
A transformer-based large language model operates as follows. Given an input sequence of tokens x = (x₁, x₂, ..., xₙ), the model computes a sequence of contextualised representations through multiple layers of multi-headed self-attention and feed-forward transformations. At each generation step, these representations are projected onto a probability distribution over the vocabulary V through a softmax function, and the next token is selected by sampling from this distribution (Vaswani et al., 2017). The output is built token by token, with each token selection conditional on all previously selected tokens and the original input.
This architecture satisfies property P1 directly and by construction. The softmax projection produces a probability distribution over all tokens in V at every generation step, meaning the output is fundamentally a sample from a probability distribution rather than a deterministic function of the input. Even in the limiting case where temperature is set to zero and argmax decoding is used, the output remains a function of learned statistical parameters θ that were estimated from training data rather than a logical derivation from the specific input presented at inference time. The distinction is fundamental: a logical derivation produces an output that is correct by construction given correct premises; a statistical estimation produces an output that is probable given training data, which is not the same thing and does not satisfy the same verifiability requirements.
Property P2 is satisfied because the intermediate computational states through which the transformer passes in generating its output, specifically the attention weight matrices at each layer, the key-value computations, and the token probability distributions at each generation step, are transient computational artifacts that are discarded after the output is produced. They are not preserved as part of the output, not stored as an audit trail, and not recoverable from the output after the fact. The output of an LLM is a token sequence. It does not carry with it the chain of intermediate computations that produced it, and there is no mechanism within the standard transformer architecture for producing such a chain in the form required by the audit trail condition of FEI.
Property P3 is satisfied definitionally, as sequential token sampling over a finite vocabulary is the fundamental generative mechanism of transformer-based language models.
Since LLMs satisfy P1, P2, and P3 by construction, the Stochastic Contamination Theorem applies directly: any LLM operating on financial data and producing outputs admitted into a financial data system as financial records will stochastically contaminate that system and violate the Financial Epistemic Integrity condition.
5.2 Why Retrieval Augmented Generation Does Not Resolve the Problem
Retrieval augmented generation (RAG) is the most widely cited mitigation strategy for LLM deployment in financial contexts. RAG architectures augment the LLM’s generation process with a retrieval component that fetches relevant documents from an external knowledge base and provides them as context during generation. The intuition is that grounding the model’s output in retrieved documents reduces its reliance on potentially stale or incorrect parametric knowledge, thereby reducing hallucination rates.
The empirical record on RAG’s effectiveness is instructive. Research published at ICLR 2025 found that RAG models can still produce hallucinations by generating outputs that conflict with the retrieved information, even when that information is accurate and relevant, because the generation process continues to balance parametric knowledge against retrieved context through the same attention mechanism that governs all transformer generation (Sun et al., 2025). Research on financial domain RAG systems has documented temporal inconsistencies in which models correctly retrieve a financial figure but associate it with the wrong date or entity, producing a contaminated record that is internally consistent but factually wrong (arXiv:2602.05723, 2026). The hallucination rate in the best-performing RAG configurations across clinical and financial domains remains measurable and non-zero, with self-reflective RAG achieving rates of approximately 5.8% in controlled evaluations (Tan et al., 2025).
The theoretical reason RAG cannot resolve the contamination problem is more fundamental than the empirical evidence alone suggests. RAG reduces the probability that an LLM will generate an incorrect output by providing better context. It does not alter the architecture of the generation process. The LLM in a RAG system still satisfies properties P1, P2, and P3: its outputs are still samples from a probability distribution, its intermediate states are still not preserved as an auditable derivation chain, and its generation is still token-by-token sequential sampling over a finite vocabulary. RAG changes the quality of the inputs to the probabilistic process. It does not make the process deterministic, and it does not produce a derivation chain from retrieved documents to output that satisfies the audit trail condition of FEI.
The contamination problem, as defined in Section 3, is not that LLMs produce incorrect outputs too frequently. It is that their outputs lack the derivation traceability required by the Financial Epistemic Integrity condition, regardless of their accuracy. A RAG system that produces a correct financial record 99.9% of the time still produces, on every run, an output without a traceable derivation chain, and therefore still produces Stochastic Contamination on every run. The correctness rate is irrelevant to the contamination. The architecture is determinative.
5.3 Why Domain Fine-Tuning Does Not Resolve the Problem
Domain fine-tuning adapts a pre-trained LLM to a specific domain by continuing its training on domain-specific data. Financial LLMs fine-tuned on accounting standards, regulatory documents, company filings, and transaction records have been shown to improve performance on domain-specific tasks and reduce certain categories of hallucination. The argument for fine-tuning in financial contexts is that a model deeply trained on financial data will develop better calibrated probability distributions over financial content, producing outputs that are more reliably correct.
The empirical finding that undermines this argument is precisely documented in the literature: fine-tuning on novel information can initially decrease hallucination rates only for them to subsequently increase, a phenomenon known as knowledge instability that results from the tension between new domain knowledge and the model’s existing parametric knowledge (Gekhman et al., 2024). More fundamentally, the theoretical literature has established that for broad classes of language generation tasks, any model that generalises beyond its training data will either hallucinate invalid outputs or suffer mode collapse, failing to produce the full range of valid responses (Kleinberg and Mullainathan, 2024). Fine-tuning does not eliminate this fundamental trade-off. It shifts the model’s performance characteristics within the space defined by it.
The theoretical reason fine-tuning cannot resolve the contamination problem is identical to the reason RAG cannot: it does not alter the architectural properties P1, P2, and P3 that cause Stochastic Contamination. A fine-tuned LLM still generates outputs by sampling from a probability distribution over a vocabulary. It still produces no auditable derivation chain from input to output. It still satisfies all three properties that the theorem proves are sufficient for Stochastic Contamination. Fine-tuning changes the parameters θ of the model, not the architecture of its generation process, and it is the architecture of the generation process, not the values of θ, that produces the contamination.
5.4 Why Constitutional Constraints Do Not Resolve the Problem
Constitutional AI and related constraint mechanisms impose rules on LLM output through training objectives, output filtering, or post-processing verification. The idea is that an LLM constrained to follow certain principles, including accuracy principles and domain-specific rules, will produce outputs that are more reliable and more consistent with established facts. Some financial AI deployments implement verification layers that check LLM outputs against structured databases before admitting them into downstream systems.
Constitutional constraints can reduce the frequency of certain categories of hallucinated output. They cannot resolve the contamination problem for two reasons. First, the verification mechanism that checks LLM outputs against a database is itself performing a comparison between two data objects: the LLM’s output and the database record. Where the two agree, the verification passes the output. Where they disagree, the output is rejected or flagged. But this mechanism only catches contamination that produces a result inconsistent with the database. Contamination that produces a plausible, database-consistent but incorrect result, for example a transaction classified in an adjacent but incorrect category, is invisible to the verification layer. The verification checks consistency, not derivation.
Second, and more fundamentally, the post-processing verification mechanism does not produce an auditable derivation chain from source data to output in the sense required by FEI property (iii). It produces a record that an output passed a consistency check. This is not the same as a record that an output was derived from source data through an auditable logical process. A financial record that passed a consistency check against a database is not a financially valid record in the FEI sense. It is a record that was found to be consistent with another record, which is a weaker property that does not satisfy the audit trail condition.
5.5 The Capability Fallacy
A common response to the disqualification argument is that as LLMs become more capable, their effective error rate approaches zero, and at sufficiently low error rates the contamination risk becomes negligible. This argument confuses accuracy with verifiability and misunderstands the nature of the Financial Epistemic Integrity condition.
FEI is a binary property. A financial record either has a traceable derivation from source data or it does not. The frequency with which an LLM produces numerically correct outputs is irrelevant to whether those outputs have traceable derivations, because the absence of a derivation chain is an architectural property of the generation process, not a property of any individual output. A highly capable LLM that produces correct financial records 99.99% of the time produces, on every single run, outputs without traceable derivation chains. Every one of those outputs is a contaminated record in the sense defined in Section 3, because Corollary 1 of the theorem establishes that Stochastic Contamination is independent of numerical accuracy.
The capability fallacy is particularly dangerous in the financial context because it provides a seemingly rational basis for deploying LLMs in financial data processing while dismissing contamination concerns as theoretical. It is not theoretical. As demonstrated empirically by research finding that broad classes of language models face a fundamental trade-off between hallucination and mode collapse that cannot be escaped through capability improvement alone (Kleinberg and Mullainathan, 2024), the contamination problem is not a function of insufficient capability. It is a function of architecture. Increasing capability makes the contamination less frequent. It does not make the contamination detectable, recoverable, or compatible with the Financial Epistemic Integrity condition.
5.6 The Permanent Nature of the Disqualification
The disqualification of LLMs from financial data processing is not a temporary limitation pending further research or development. It is a permanent consequence of the transformer architecture as long as that architecture generates outputs through probabilistic token sampling rather than deterministic logical derivation.
A transformer-based LLM that generated outputs through deterministic logical derivation would not be an LLM in any meaningful sense. It would be a rule-based system with a natural language interface: a system that applies explicit logical rules to structured inputs and produces outputs that are traceable to those rules. Such a system might be architecturally compatible with the Financial Epistemic Integrity condition, and might constitute a useful tool in financial data processing, but it would not be a large language model. The capability that makes LLMs valuable, their ability to generalise across contexts, synthesise information from diverse sources, and generate fluent and contextually appropriate responses to novel inputs, is a direct consequence of the probabilistic architecture that produces Stochastic Contamination. It is not possible to preserve the former while eliminating the latter within the transformer architecture. The disqualification and the capability are the same thing, seen from different perspectives.
This is the conclusion that the financial services industry, the accounting profession, and their regulators have not yet confronted directly. The question is not how to make LLMs safe enough to use in financial data processing. The question is what class of system should be used instead, and what properties that system must have to satisfy the Financial Epistemic Integrity condition. Section 8 addresses the first question through the live case. Section 9 addresses the second through the Financial AI Fitness Standard.
6. The Regulatory Gap
The Stochastic Contamination Theorem establishes that probabilistic AI systems operating on financial data necessarily violate the Financial Epistemic Integrity condition. The regulatory frameworks governing AI in financial contexts do not contain this finding, do not reflect the conceptual vocabulary required to act on it, and in several cases are actively encouraging the deployment of precisely the systems that the theorem disqualifies. This section examines each relevant framework in turn, identifies the specific gap in each, and proposes the minimum amendment required to close it.
6.1 The Financial Reporting Council
The FRC published its first guidance on AI in audit in mid-2025, followed by further guidance on generative and agentic AI tools in audit engagements in March 2026 (FRC, 2026). The guidance represents the most substantive regulatory engagement with AI in financial contexts produced by any UK body to date. It addresses risk identification, documentation requirements, human oversight obligations, and quality assurance processes for AI-assisted audit work. It does not make an architectural distinction between probabilistic and deterministic AI systems. Its approach is to identify the risks that generative AI tools introduce and to specify mitigations: human review of AI outputs, documentation of tools used, quality controls over AI-generated work products.
This approach has a structural limitation that the guidance does not acknowledge. The mitigations it specifies, human review of AI outputs and documentation of tools used, address the symptoms of Stochastic Contamination without addressing its cause. As established in Section 3.3, contaminated outputs produced by LLMs are undetectable through standard review procedures precisely because they are designed to be plausible and pattern-consistent. Human review of AI-generated audit work products will not reliably catch contamination that has no surface indicators of error. Documentation of the AI tool used does not produce the derivation chain from source data to output that the audit verifiability property of FEI requires. The FRC’s guidance makes probabilistic AI use in audit safer in the sense of more documented and more scrutinised. It does not make it FEI-compliant.
The gap in the FRC framework is the absence of a requirement that AI systems used in audit engagements produce outputs with auditable derivation chains traceable to source data. Without this requirement, audit firms can deploy LLMs in audit work, document their use, subject their outputs to human review, and remain in compliance with FRC guidance while introducing Stochastic Contamination into the audit process. The amendment required is: the addition to FRC guidance of an explicit requirement that AI systems used in audit engagements satisfy the audit trail condition, meaning that every AI-generated output must be accompanied by an auditable record of the logical steps through which the output was derived from source evidence.
6.2 The Financial Conduct Authority
The FCA has engaged extensively with AI in financial services since 2024, publishing research notes, running an AI lab, conducting a Supercharged Sandbox in partnership with NVIDIA, and soliciting feedback through its AI Input Zone (FCA, 2024; FCA, 2025). Its approach reflects the UK government’s pro-innovation stance: rather than establishing prescriptive requirements, the FCA is applying its existing regulatory principles, consumer duty, operational resilience, model risk management, and systems and controls requirements, to AI deployments case by case.
The FCA’s existing framework contains requirements that are partially relevant to the contamination problem. Consumer duty requires that firms deliver good outcomes for retail customers, which implies that AI systems producing contaminated financial records that lead to incorrect consumer outcomes are in breach. Operational resilience requirements apply to critical AI systems. Model risk management guidance requires firms to understand and manage the risks of models used in decision-making.
None of these requirements, however, prohibits the use of probabilistic AI in financial data processing on architectural grounds or requires that AI outputs be derivation-traceable to source data. The FCA’s framework is outcome-focused rather than architecture-focused: it asks whether AI deployments produce good outcomes rather than whether the architectural properties of the AI system are compatible with the FEI condition. The contamination problem cannot be addressed by outcome monitoring alone, because the undetectability property established in Section 3.3 means that contaminated outcomes are not reliably distinguishable from uncontaminated outcomes through ex post monitoring. By the time contamination is detected, it has propagated through the financial data system and into the downstream decisions that depended on it.
The gap in the FCA framework is the absence of any requirement that AI systems processing financial data in FCA-regulated firms satisfy architectural conditions equivalent to the FEI condition. The amendment required is: the addition to the FCA’s model risk management guidance and consumer duty framework of a requirement that AI systems generating financial records, reports, or assessments satisfy a minimum architecture standard requiring deterministic, auditable derivation chains from source data to output, and that systems not satisfying this standard be prohibited from generating records or assessments admitted directly into financial data systems without independent re-derivation from source.
6.3 The IAASB and International Auditing Standards
The IAASB is conducting a gap analysis of its International Standards on Auditing to assess their alignment with technological developments, including AI (IAASB, 2024). ISA 500 governs audit evidence and requires that audit evidence be sufficient and appropriate, meaning relevant and reliable. ISA 315 governs the identification and assessment of risks of material misstatement and requires auditors to obtain an understanding of the entity and its environment, including its information systems. Neither standard contains requirements specific to AI-generated financial data or to the architectural properties of systems that produce financial records subject to audit.
The IAASB gap analysis, to the extent its results are publicly available, addresses questions of how existing standards apply to AI-assisted audit procedures rather than whether the AI systems being audited satisfy conditions compatible with audit verifiability. This is precisely the wrong question. The question that matters is not whether ISA 500 applies to AI-generated audit evidence. It is whether AI-generated audit evidence can satisfy the reliability requirement of ISA 500 when it was produced by a system that does not preserve an auditable derivation chain from source data to output.
The answer the Stochastic Contamination Theorem provides is that it cannot. AI-generated audit evidence produced by a probabilistic system is not reliable in the ISA 500 sense, regardless of its apparent accuracy, because its reliability cannot be established through reference to an auditable derivation process. The contamination is not a reliability risk that auditors can assess through professional judgment. It is a structural property of the evidence that makes reliability assessment by standard audit procedures impossible.
The gap in the IAASB framework is the absence of a requirement in ISA 500 that audit evidence produced by AI systems must be accompanied by an auditable derivation record establishing its traceability to source. The amendment required is: a revision of ISA 500 to add a reliability criterion specific to AI-generated evidence, requiring that evidence produced by automated systems be accompanied by a derivation record satisfying the audit trail condition, and specifying that evidence produced by probabilistic generative systems without such a record does not satisfy the reliability requirements of the standard.
6.4 The PCAOB
The Public Company Accounting Oversight Board oversees the audits of US public companies and broker-dealers and sets auditing standards applicable to those engagements. PCAOB standards, like IAASB standards, address audit evidence quality through sufficiency and appropriateness requirements without making architectural distinctions between AI system types. The PCAOB has issued alerts and staff guidance on the use of technology in audits, including AI, but these focus on auditor responsibilities in relation to AI-assisted procedures rather than on the properties that AI systems must have to produce evidence compatible with PCAOB audit standards.
The PCAOB gap parallels the IAASB gap: its standards require appropriate audit evidence without specifying that appropriateness, in the context of AI-generated evidence, requires a derivation chain traceable to source data. Given that the Sarbanes-Oxley Act requirements for internal controls over financial reporting depend on the integrity of the financial data those controls govern, and given that contaminated financial data produced by probabilistic AI systems undermines that integrity in ways that standard internal control frameworks are not designed to detect, the PCAOB gap has direct implications for public company financial reporting reliability and investor protection.
The amendment required is equivalent to that proposed for the IAASB: a revision of PCAOB evidence standards to require that AI-generated audit evidence satisfy an auditable derivation requirement, and that probabilistic generative systems be prohibited from producing evidence admitted directly into audit documentation without independent verification from source data.
6.5 HMRC and Making Tax Digital
HMRC’s Making Tax Digital programme requires that businesses keep digital records and submit returns using compatible software. From April 2026, the programme requires self-employed taxpayers and landlords with income above £50,000 to use MTD-compatible software, with the threshold reducing progressively through 2028 (HMRC, 2025). The programme specifies that software must be capable of producing digital records and submitting quarterly updates and returns. It does not specify architectural requirements for the software, and in particular, it neither prohibits the use of probabilistic AI components in MTD-compatible software nor requires that software-generated financial records satisfy the audit trail condition.
HMRC is simultaneously mandating digital record-keeping through MTD and investing in AI-assisted compliance checking through its Connect data analytics system and broader AI transformation programme (HMRC Transformation Roadmap, 2025). HMRC is working with industry to produce principles for AI in tax software, with a software roadmap due in 2026. As of the time of writing, no architectural requirements on the AI systems embedded in MTD-compatible software exist. Software using probabilistic AI components to classify transactions, generate expense descriptions, or produce tax computations can be MTD-compliant while producing stochastically contaminated financial records that HMRC’s own systems cannot distinguish from uncontaminated records.
This creates a situation of particular concern. HMRC’s Connect system identifies compliance risks through pattern analysis of submitted data. Contaminated financial records produced by probabilistic AI are, by the undetectability property established in Section 3.3, pattern-consistent and plausible. They will not reliably trigger Connect’s anomaly detection. HMRC therefore faces the prospect of receiving, at scale, MTD-compliant submissions containing contaminated data that its compliance systems cannot detect, contributing to the tax gap through a mechanism that its current analytical infrastructure is not designed to identify.
The amendment required is: the inclusion in HMRC’s software requirements for MTD-compatible software of an architectural standard specifying that any AI components used in transaction classification, financial record generation, or tax computation must produce outputs with auditable derivation chains traceable to source data, and that probabilistic generative AI components not satisfying this requirement are prohibited from generating financial records admitted directly into MTD submissions.
6.6 Companies House
Companies House, operating under enhanced powers granted by the Economic Crime and Corporate Transparency Act 2023, has developed significant new capabilities to query and remove false, misleading, or incorrect information from the company register (Companies House, 2025). Identity verification requirements have been introduced for directors and persons of significant control, and the registrar has new powers to investigate and strike off companies registered on false bases.
These reforms address the integrity of information submitted to the register through authentication and verification of the identities of those submitting it. They do not address the integrity of the financial information itself, specifically the annual accounts and confirmation statements that companies file, in terms of the processing systems that generated those financial records. A company whose accounts were produced using probabilistic AI-assisted accounting software will file accounts that are Companies House-compliant provided they are filed by a verified director. The contamination in the underlying financial records does not affect Companies House compliance because Companies House has no architectural requirements for the systems that generated the filed accounts.
The Companies House gap is narrower in scope than the other frameworks, but is significant because filed accounts are public documents that underpin credit decisions, investment analysis, supply chain due diligence, and regulatory assessments. Contaminated accounts that are Companies House-compliant are nonetheless unreliable as a basis for the economic decisions that public company filings are designed to support.
The amendment required is: the inclusion in Companies House filing requirements of a data quality standard specifying that accounts produced using AI systems must have been generated by systems satisfying the audit trail condition, and that accounts generated by probabilistic AI systems without auditable derivation chains must be accompanied by a disclosure to that effect.
6.7 The Wider Regulatory Implication
The pattern across all six frameworks is consistent. Each framework addresses the risks of AI in financial contexts through outcome requirements, disclosure obligations, human oversight mandates, and risk management principles. None makes the architectural distinction between probabilistic and deterministic systems that the Stochastic Contamination Theorem establishes is necessary to protect financial data integrity. Each framework is therefore capable of being satisfied by deployments of probabilistic AI systems that are producing Stochastic Contamination in the financial data they process.
The common amendment required across all frameworks is an architectural classification requirement: before specifying what governance, oversight, or disclosure obligations apply to an AI system operating on financial data, regulators must first determine whether the system’s outputs are produced through a deterministic, auditable derivation process or through probabilistic generation. Systems satisfying the former may, subject to appropriate rule set audit and output monitoring requirements, be compatible with the Financial Epistemic Integrity condition. Systems satisfying the latter are not, and should be prohibited from generating financial records admitted directly into financial data systems regardless of their accuracy benchmarks, governance arrangements, or human oversight protocols.
The current regulatory conversation asks how to govern probabilistic AI in financial contexts. The Stochastic Contamination Theorem establishes that the correct question is whether probabilistic AI should be permitted in financial data processing at all. The answer the theorem provides is that it should not, for the same reason that a scale that produces measurements drawn from a probability distribution rather than from the object being weighed cannot be used for legal trade: the instrument is categorically incompatible with the verification requirements of the domain in which it is being deployed.
7. Systemic Implications: From Transaction to Market
The analysis in Sections 2 through 6 addresses Stochastic Contamination at the level of individual financial records and the regulatory frameworks that govern their production. This section extends the argument to the systemic level, tracing the propagation pathway of contaminated financial data from its point of introduction through statutory audit, published financial statements, tax submissions, capital market valuations, credit assessments, and macroeconomic accounting. The purpose is to establish that Stochastic Contamination is not a firm-level data quality problem. It is a systemic integrity risk whose consequences scale with the adoption of probabilistic AI in financial data processing across the economy.
7.1 The Propagation Architecture of Financial Data
Financial data does not exist in isolation. Every figure in a company’s financial statements is connected, through a chain of derivation, to transaction-level records. Those statements are connected, through audit, to the assurance process that certifies them as reliable. The certified statements are connected, through disclosure, to the information set on which investors, creditors, analysts, and counterparties base decisions. Those decisions are connected, through capital allocation, to the prices of securities, the terms of credit, the valuations of businesses, and the aggregate financial statistics that inform macroeconomic policy.
This propagation architecture means that contamination introduced at the transaction level does not remain at the transaction level. It travels upward through the financial reporting chain and outward through every decision that depends on the financial data it has contaminated. The conservation propagation property established in Section 2.1 describes the vertical dimension of this propagation: an error at the transaction level propagates to every balance and every report derived from that transaction. The systemic analysis in this section describes the horizontal dimension: the propagation of contaminated data across the institutions, markets, and policy frameworks that depend on financial reporting for their functioning.
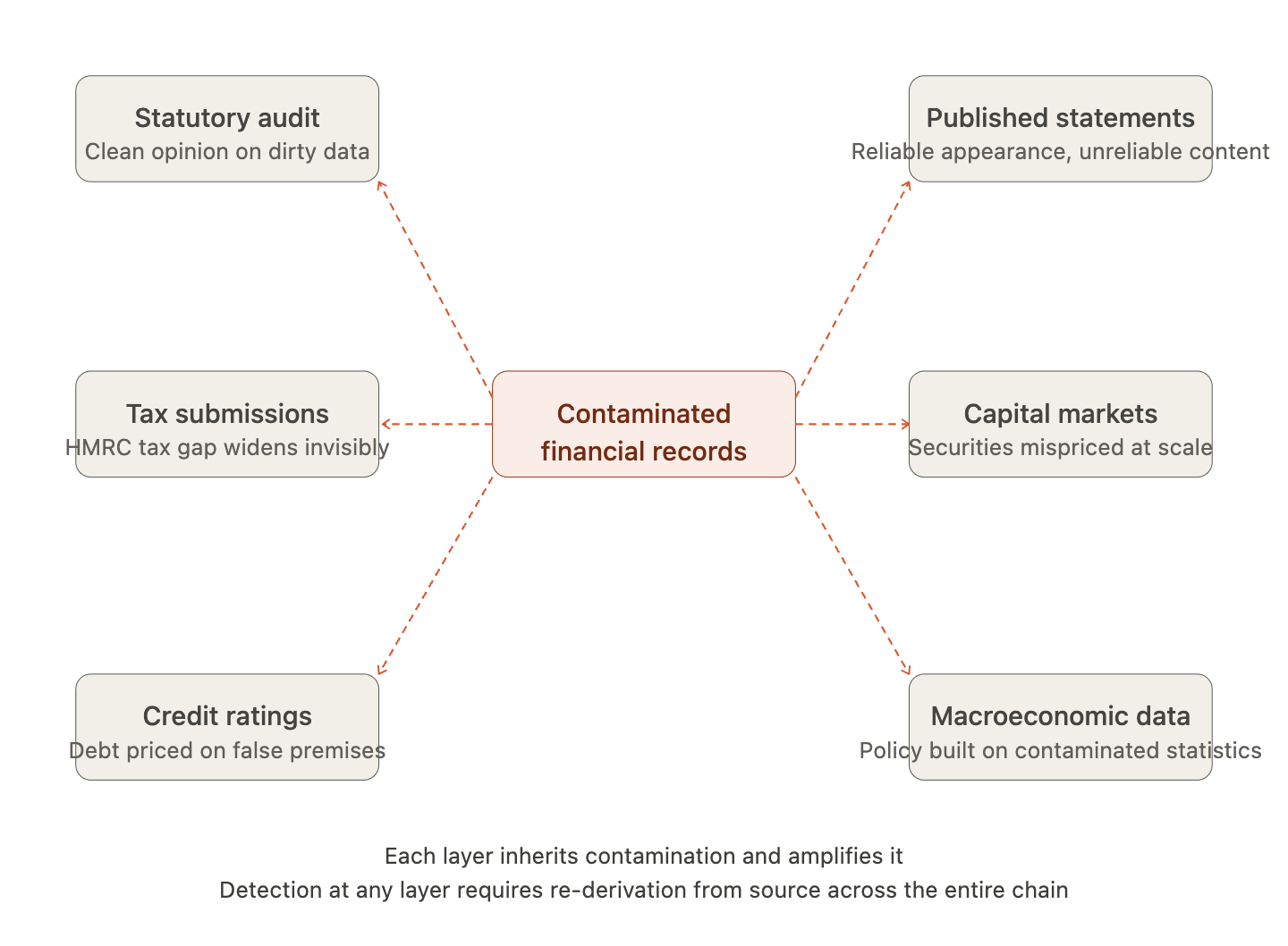
7.2 Contamination in Statutory Audit
Statutory audit is the primary mechanism through which societies assure themselves that published financial statements are reliable. The audit process samples transactions, examines evidence, tests controls, and forms a judgment about whether the financial statements as a whole present a true and fair view. This process is designed to catch errors introduced by human processing: misclassifications, omissions, duplicate entries, and deliberate misstatements that leave detectable traces in the accounting records.
As established in Section 3.3, Stochastic Contamination produced by probabilistic AI systems does not leave the traces that audit procedures are designed to detect. A contaminated transaction classification produced by an LLM is internally consistent, numerically plausible, and pattern-compatible with the surrounding financial data. Standard audit sampling procedures select transactions for examination based on risk indicators, materiality thresholds, and analytical anomalies. A contaminated record that produces none of these signals will not be selected for examination. A contaminated record that is selected for examination will be compared against its source document by the auditor, and if the LLM’s classification is consistent with a plausible reading of that document, the auditor will find no evidence of error. The contamination will survive the audit.
The FRC’s 2024-25 audit inspection results indicate that 26% of audits reviewed required more than limited improvements, representing a material quality deficiency rate under current conditions where LLM use in financial processing is still limited (FRC, 2024). As probabilistic AI adoption in accounting and financial reporting increases, the contamination problem will scale with it. Audit procedures that cannot detect LLM-introduced contamination will produce clean opinions on contaminated financial statements at a rate that increases with LLM adoption, while the audit profession remains structurally unaware of the gap because the contamination has no observable signature.
The consequence for statutory audit is a progressive erosion of assurance value that is invisible to the assurance process itself. An audit opinion on financial statements produced with LLM assistance provides the same formal assurance as an opinion on statements produced without it, but the underlying probability that the opinion correctly certifies the statements as reliable is lower, by an amount that cannot be quantified because the contamination cannot be measured. Assurance that cannot be calibrated is not assurance; it is the appearance of assurance, which is more dangerous than its absence because it misleads the parties who rely on it.
7.3 Contamination in Published Financial Statements
Published financial statements are the canonical representation of a company’s financial position. They are the basis on which shareholders assess management performance, on which boards make strategic decisions, on which lenders set credit terms, on which analysts produce forecasts, and on which courts assess liability in commercial disputes. Their reliability is a foundational condition for the functioning of the market economy.
The history of major accounting failures, from Enron and WorldCom through Wirecard and Patisserie Valerie, demonstrates the systemic consequences of financial statements that misrepresent economic reality. Each of these failures involved deliberate misstatement rather than AI-induced contamination, but the market consequences, catastrophic share price collapses, creditor losses, employee pension destruction, and counterparty harm, were identical in character to the consequences that would follow from contaminated financial statements that later required restatement.
Audit Analytics’ long-run analysis of financial statement restatements indicates that most restatements carry negative income impact, meaning corrections are systematically adverse to previously reported figures (Audit Analytics, 2023). The economic harm from restatements is not confined to the correction event. It includes the mispricing that occurred between the original publication and the correction, and the capital allocation decisions made during that period on the basis of figures that were not reliable. By the time the restatement occurs, the harm is already done: investment decisions have been made, credit has been extended, contracts have been signed, and pensions have been valued on the basis of financial statements that did not accurately represent the company’s financial position.
Stochastic Contamination introduces a new pathway to this outcome that differs from deliberate misstatement in one crucial respect: there is no intent and therefore no detection mechanism oriented toward catching it. Deliberate misstatement involves actors who know the statements are wrong and who therefore leave a trail of concealment that forensic accounting and regulatory investigation can follow. Stochastic Contamination involves a processing system that produces plausible outputs without intent and without concealment, leaving no trail that standard detection mechanisms can follow. The resulting financial statements may be incorrect for reasons that are undetectable, uncorrectable without complete re-derivation from source, and entirely invisible to the audit process, the board, and the shareholders who relied on them.
7.4 Contamination in Tax Submissions
The connection between financial data quality and tax compliance is direct and empirically documented. HMRC’s Measuring Tax Gaps 2025 edition attributes 31% of the £46.8 billion UK tax gap to failure to take reasonable care and a further 15% to error, together representing 46% of the gap attributable to informational defect rather than deliberate evasion (HMRC, 2025). Research indicates that most errors in tax reporting originate in inadequate financial record-keeping practices at the transaction processing stage, before data reaches HMRC or its agents (HMRC, 2019).
Stochastic Contamination is a specific and novel form of the informational defect that produces tax gap contributions through error and failure to take reasonable care. A contaminated transaction classification produced by an LLM, for example a capital expenditure classified as a revenue expense, or a personal cost classified as a business expense, produces an incorrect tax computation. The taxpayer or agent submitting the return does so in good faith, relying on accounting records that appear correct. HMRC’s Connect system receives a submission that is internally consistent and pattern-compatible with similar businesses. The contamination is invisible to the taxpayer, the agent, and the tax authority alike.
As Making Tax Digital mandates the use of compatible software across an expanding population of taxpayers from 2026, and as that software increasingly incorporates probabilistic AI components for transaction classification and financial record generation, the scale of contamination in submitted tax data will increase. The tax gap contribution attributable to informational defect will grow, not because taxpayers are less careful or less honest, but because the systems they are required to use are architecturally incapable of producing the verified, auditable financial records that accurate tax compliance requires. The regulatory mandate is actively creating the conditions for the problem it is designed to address.
7.5 Contamination in Capital Markets
Capital markets price securities on the basis of information about the companies whose securities are traded. That information flows primarily through published financial statements, analyst research, and company disclosures, all of which depend ultimately on the integrity of the underlying financial data. A contaminated financial statement that passes audit and is published as reliable becomes part of the information set on which market participants price the company’s securities. If the contamination produces a material misstatement of earnings, assets, or liabilities, the securities price will reflect a misstatement of the company’s true financial position.
The consequences of this mispricing are not confined to the direct parties to transactions in that security. Mispriced securities affect index compositions, benchmark weights, portfolio valuations, derivatives prices, and the relative cost of capital across the economy. A contaminated financial statement in a company included in a major equity index contaminates the index valuation. Pension funds, sovereign wealth funds, and retail investors holding index products are exposed to the mispricing without any mechanism for detecting or correcting it. Credit rating agencies assessing the company’s debt rely on the same contaminated financial statements. The contaminated rating affects the pricing of the company’s debt across its entire capital structure and the capital requirements of financial institutions holding that debt.
The systemic risk dimension of financial statement contamination was recognised in the regulatory response to the major accounting scandals of the early 2000s, producing the Sarbanes-Oxley Act in the United States and equivalent reforms in Europe. Those reforms were designed to address deliberate misstatement. Stochastic Contamination is a new pathway to the same systemic risk that those reforms do not address, because its mechanism, probabilistic AI generating plausible but unverifiable outputs, was not a feature of the financial landscape in 2002.
7.6 Contamination in Macroeconomic Accounting
National accounts, economic statistics, and macroeconomic indicators are constructed from aggregated financial data produced by the corporate sector. GDP, productivity statistics, sector-level investment data, and tax revenue forecasts depend on the accuracy of the financial records that companies submit to HMRC, Companies House, and statistical agencies. If those records are systematically contaminated by probabilistic AI processing at scale, the contamination propagates into national statistics.
The Office for National Statistics relies on surveys of business financial data and on administrative data from HMRC to construct national accounts. Contaminated financial records systematically misclassifying capital expenditure as revenue expenditure, or misclassifying business income categories, would produce systematic errors in national accounts that track these categories. The errors would be consistent, pattern-compatible, and structurally invisible to the data quality checks that statistical agencies apply, for the same reason they are invisible to audit procedures: they are produced by systems optimised to generate plausible outputs.
The macroeconomic policy implications of systematically contaminated national statistics are significant. Interest rate decisions, fiscal policy settings, and regulatory capital requirements depend on accurate economic data. Systematic contamination of the data underlying those decisions introduces a new source of policy error that cannot be identified or corrected through standard statistical quality control, because the contamination has no detectable signature in the aggregate data. The errors look like economic facts rather than data artifacts, and the policies based on them will be correspondingly misguided.
7.7 The Accumulation Dynamic
The systemic risk from Stochastic Contamination accumulates as probabilistic AI adoption in financial data processing increases. Each additional firm that deploys an LLM in its accounting or financial reporting processes adds a new source of contamination to the financial system. Each contaminated financial statement certified by audit adds another layer of false assurance. Each contaminated tax submission contributes to a tax gap whose informational component grows invisibly. Each contaminated annual report filed at Companies House adds to a public register whose reliability is progressively undermined.
The accumulation dynamic has a self-reinforcing dimension. As contaminated financial data becomes more prevalent in the datasets used to train and fine-tune financial AI systems, future AI systems will learn from contaminated examples, producing models whose outputs are calibrated to be consistent with contaminated financial norms rather than true financial norms. The contamination spreads not only through the financial system but into the AI systems that process the financial system, creating a feedback loop that amplifies the problem over time.
This accumulation dynamic is the strongest argument for regulatory intervention at the architecture level rather than the output level. By the time contamination is observable in macroeconomic statistics, audit failure rates, or systematic restatement patterns, it will have been embedded in financial data, AI training corpora, and market prices for years. The irrecoverability property established in Section 3.4 applies not only to individual contaminated financial data systems but to the financial system as a whole: once contamination is embedded at systemic scale, removing it requires re-derivation from primary source data across the entire economy, which is not a practical proposition.
The window for architecture-level regulatory intervention is therefore not indefinitely open. It closes as probabilistic AI adoption in financial data processing reaches a threshold beyond which the contamination is too deeply embedded to address without systemic reconstruction. The evidence assembled in this paper establishes that we are in the early stages of that adoption curve. The regulatory response needs to address architectural requirements now, before the accumulation dynamic reaches the point at which intervention is either insufficient or impossible.
8. A Live Case: Contamination-Free Processing in Production
The theoretical framework developed in Sections 2 through 4 and the systemic risk analysis in Section 7 establish the contamination problem analytically. This section provides empirical grounding: evidence from a live production deployment of a deterministic financial processing system operating across UK micro-businesses that demonstrates, in observable data, what contamination-free financial processing looks like and what happens when it is compromised by human intervention carrying the same cognitive properties as probabilistic AI output generation.
The system described in this section is not named. It is an active commercial deployment operating under ongoing patent application, and its proprietary architecture is protected accordingly. What can be reported, and what is reported here, are the empirical outcomes: the processing performance, the error characteristics, and the specific data produced when the system was operated in fully automated mode compared to when human operators were introduced into the processing loop. The outcomes are the evidence. The architecture that produced them is described only at the level of principle.
8.1 System Properties Relevant to the FEI Condition
The system satisfies the Financial Epistemic Integrity condition as defined in Section 2.4 through three architectural properties that correspond directly to the three FEI requirements.
On the conservation property: the system applies explicit classification rules to structured transaction data in a manner that preserves the accounting identity at every processing step. Every transaction is processed through a rule chain that is constructed to maintain conservation as an invariant. No transaction can be admitted into the accepted financial state in a configuration that violates the conservation constraint. Conservation is not checked after the fact. It is guaranteed by the processing architecture before any output is produced.
On the legal obligation property: every output produced by the system is the result of the application of a specific, named rule from the rule library to a specific input transaction with specific characteristics. The rule applied, the characteristics of the input that triggered it, and the output produced are all recorded at the point of processing. The demonstrability requirement is therefore satisfied by construction: for any financial record produced by the system, the source evidence, the rule applied, and the derivation from source to output are available and auditable at any subsequent point.
On the audit verifiability property: the system produces, as an integral component of every output, an unbroken derivation record tracing the output from the source transaction through the classification process to the final financial record. This record is not retrospective documentation. It is produced simultaneously with the output as a structural property of the processing architecture. The audit trail condition is therefore satisfied not as a compliance requirement but as an architectural consequence.
The system satisfies all three FEI properties. By the Stochastic Contamination Theorem, it does not produce Stochastic Contamination. Its outputs are admissible into a financial data system without violating the FEI condition. This is the architectural baseline against which the empirical results below are measured.
8.2 Automated Processing Results
The dataset comprised 200 UK micro-business entities assessed across a 24-month period, providing a transaction population sufficient for statistically meaningful comparison. The system processed the transaction data in fully automated mode, with human review restricted exclusively to a targeted exception set: transactions whose confidence score fell below a defined threshold or whose monetary impact exceeded a defined materiality threshold.
Processing efficiency: average processing time per client per month was 12 minutes under fully automated operation, compared to 71 minutes under legacy manual processing, representing an 84% reduction.
Accuracy against materiality threshold: the system produced a defect rate of zero in the pilot dataset. Expressed in Six Sigma terms, compliance DPMO was 0 per million opportunities, exceeding the Six Sigma benchmark of 3.4 DPMO (Pyzdek and Keller, 2014).
Exception volume: typically one to two transactions per client per month required human review, representing approximately 2% to 3% of total transaction volume. This low exception rate reflects the empirical finding, established in earlier research on this dataset, that 82% of micro-business transactions complete their full cycle within the same calendar month as origination and exhibit highly predictable behavioural patterns (Cohen, 2024).
Audit trail completeness: 100% of processed transactions were accompanied by complete derivation records linking source evidence to output through the classification rule chain. No output was produced without a full audit trail. The FEI condition was satisfied for every admitted record.
These results establish the empirical baseline for contamination-free financial processing: zero material defects, complete derivation traceability, and processing efficiency substantially superior to manual processing. This is what FEI-compliant AI-assisted financial data processing looks like in production.
8.3 The Human Intervention Results and Their Interpretation
When qualified accountants were given direct access to drive the system in live production, with the automated processing logic unchanged and the rules identical, the results degraded across every measurable dimension.
Processing time increased from 12 minutes per client per month to 49 minutes, a 308% increase from the automated baseline. Error rates rose from near-zero to rates consistent with documented human processing error rates of 1% to 3% (Panko, 1998; Barchard et al., 2020), between 32 and 96 times higher than the fully automated baseline.
The mechanism of degradation is directly relevant to the contamination argument. The accountants, presented with automated outputs, shifted from allowing the system to complete its processing to actively intervening in routine processing: checking, adjusting, and occasionally overriding outputs that the system had produced correctly. Each intervention introduced the possibility of error where none had existed. Each override substituted a human judgement, subject to all the cognitive limitations established in the broader literature on human processing error, for a rule-governed derivation that was correct by construction.
From the FEI perspective, the human interventions also compromised the audit trail property. Where an accountant overrode a system output, the override substituted a human judgement for the system’s rule-governed derivation. The override is recorded as an event, but the reasoning behind it, the specific factors the accountant weighed in reaching the judgement, is not recorded in a form equivalent to the system’s derivation chain. The derivation traceability that the system produces by construction was partially replaced by human judgement that is traceable only to the identity of the person who made it, not to the logical steps that produced it.
The human intervention results therefore, demonstrate two things simultaneously. First, that the introduction of human cognitive processing into a deterministic financial data system degrades accuracy in the same way and through the same mechanisms that probabilistic AI processing would: by substituting pattern-matching and judgement for rule-governed derivation. Second, that the audit trail produced by the system under human intervention is weaker than the audit trail produced under full automation, because human judgement overrides produce records of decisions rather than records of derivations.
8.4 What the Evidence Demonstrates for the Contamination Argument
The live case provides three categories of evidence relevant to the contamination argument of this paper.
First, it demonstrates that FEI-compliant financial data processing is achievable in production at scale. The fully automated results establish that a financial processing system can satisfy all three FEI properties simultaneously, processing real transaction data for real businesses, producing zero material defects, and maintaining complete derivation traceability, without human intervention in the routine processing loop. The FEI condition is not a theoretical ideal. It is an achievable production standard.
Second, it demonstrates that the introduction of processing that lacks derivation traceability, whether from human judgment or probabilistic AI, degrades both accuracy and audit trail quality. The human intervention results and the LLM architecture are not equivalent in every respect, but they share the property that is causally relevant to the contamination argument: neither produces outputs through a deterministic, auditable derivation chain from source evidence. The human judgment produces a decision traceable to a person. The LLM produces a token sequence traceable to a probability distribution. Neither produces a derivation traceable to the logical steps connecting source evidence to output in the manner required by FEI property (iii). The degradation in both accuracy and audit trail quality that the human intervention results document is therefore the observable, production-scale correlate of the theoretical contamination argument.
Third, and most directly relevant to the regulatory argument, it demonstrates the magnitude of the accuracy differential between FEI-compliant deterministic processing and human-rate processing. An error rate 32 to 96 times higher than the FEI-compliant baseline is the empirical measure of what is at stake when probabilistic processing is admitted into financial data systems. At the scale of the UK’s 5.43 million registered companies, most of which use some form of accounting software and an increasing proportion of which will use AI-assisted software as MTD mandates expand, this differential translates into a contamination volume that dwarfs anything the current regulatory framework is designed to detect or address.
8.5 The Proof of Concept
The live case is not presented as a generalisation of the FEI-compliant architecture to all financial processing contexts. The dataset is specific, the entity type is specific, and the transaction characteristics of UK micro-businesses are not universal. What the live case demonstrates is that the alternative to probabilistic AI in financial data processing is not merely theoretical. It exists. It works. It produces better outcomes on every measurable dimension than either legacy manual processing or human-assisted processing. And it satisfies the Financial Epistemic Integrity condition that probabilistic AI systems are proven, by the theorem in Section 4, to violate.
The existence of a working, production-scale alternative to probabilistic AI in financial data processing eliminates the strongest practical argument against architectural regulation of the kind proposed in Section 6: that prohibiting probabilistic AI in financial contexts would leave no viable alternative. The alternative exists, it is operational, and it has demonstrated superior performance characteristics in the domain where the contamination risk is most acute. Regulators asking whether the Financial AI Fitness Standard proposed in Section 9 is achievable have an empirical answer: it is not only achievable, it has already been achieved.
9. The Financial AI Fitness Standard
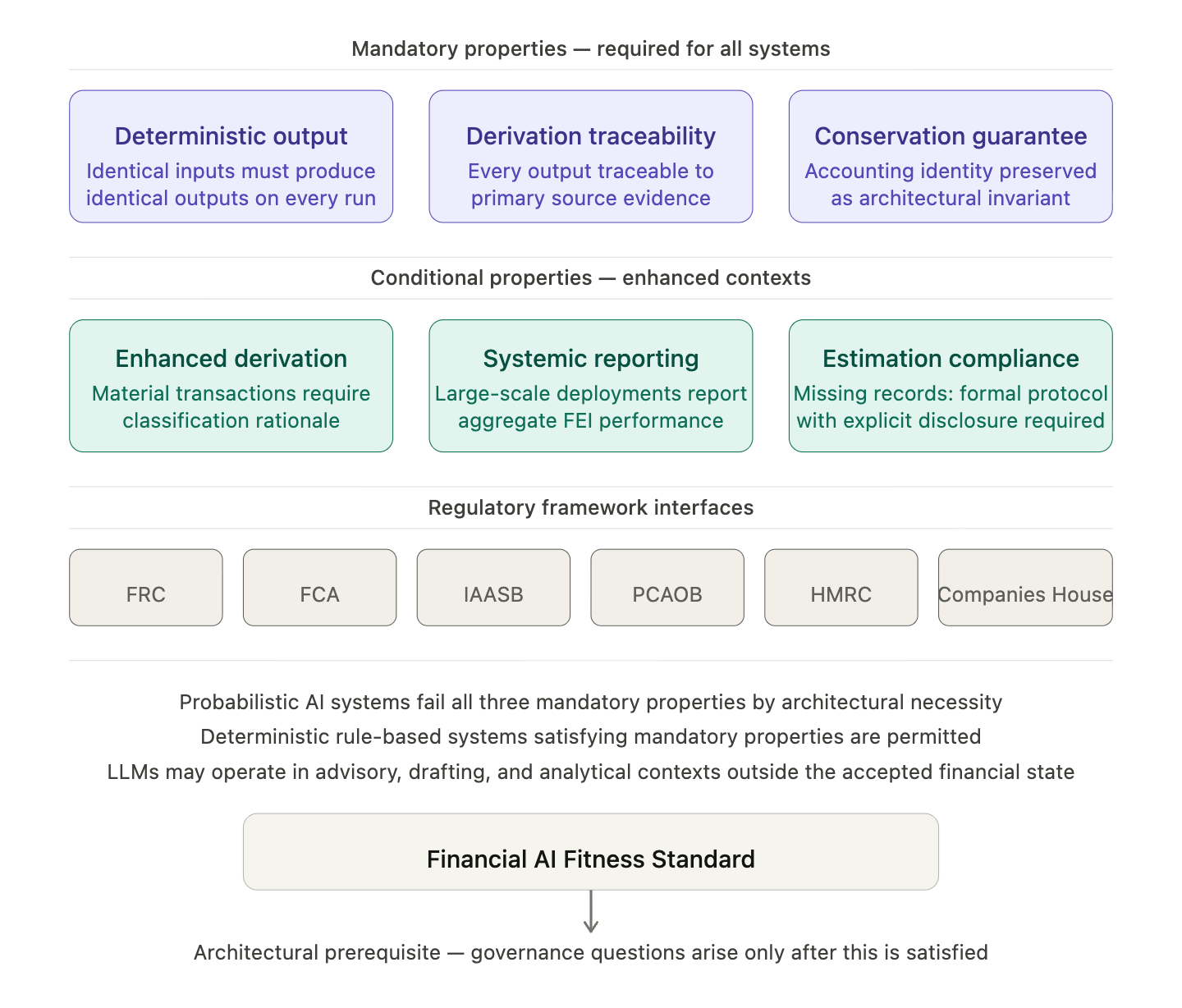
The Financial AI Fitness Standard: three mandatory architectural properties required of all AI systems operating on financial data, three conditional properties for enhanced contexts, and the six regulatory frameworks into which the standard interfaces. Compliance with the mandatory properties is an architectural prerequisite; governance, oversight, and disclosure obligations are secondary.
The analysis assembled in this paper converges on a single practical question: what properties must an AI system possess before it is permitted to operate on financial data? Section 2 established that financial data has properties, mathematical conservation, legal demonstrability, and audit verifiability, that jointly constitute the Financial Epistemic Integrity condition. Section 4 proved that probabilistic AI systems necessarily violate that condition. Section 5 demonstrated that no current mitigation strategy resolves the violation at the architectural level. Section 6 identified the specific gaps in every relevant regulatory framework. Section 7 traced the systemic consequences of contamination at scale. Section 8 provided empirical evidence that FEI-compliant processing is achievable in production.
What remains is the constructive argument: a minimum property set, derived directly from the theorem and the FEI condition, that any AI system must satisfy before operating on financial data. This paper terms that property set the Financial AI Fitness Standard. It is not a governance framework, an oversight protocol, or a disclosure requirement. It is an architectural prerequisite that must be satisfied before governance, oversight, and disclosure questions arise at all.
9.1 The Structure of the Standard
The Financial AI Fitness Standard comprises three mandatory properties and two conditional properties. The three mandatory properties correspond directly to the three components of the Financial Epistemic Integrity condition and must be satisfied by any AI system that generates financial records admitted into a financial data system. The two conditional properties apply to systems operating in specific high-stakes contexts and represent enhanced requirements above the mandatory baseline.
9.2 Mandatory Property 1: Deterministic Output Generation
A financial AI system must generate its outputs through a deterministic process, meaning that for any given set of inputs, the system produces the same output on every run. Stochastic output generation, in which outputs are samples from a probability distribution over possible outputs, is incompatible with the Financial Epistemic Integrity condition and is prohibited for systems generating financial records admitted into financial data systems.
This property directly addresses properties P1 and P3 of the Stochastic Contamination Theorem. A system satisfying this property cannot produce the stochastic output variation that constitutes Stochastic Contamination. Its outputs are determined by its rules and its inputs, not by a sampling process operating over a learned probability distribution.
The practical test for this property is straightforward: given identical inputs, does the system produce identical outputs across multiple runs? A system that fails this test is a probabilistic system and does not satisfy Mandatory Property 1. A system that passes it is deterministic in its output generation and satisfies this component of the standard.
This property does not prohibit the use of probabilistic methods in the design or training of components of a financial AI system, provided those components do not participate in output generation for financial records. A system that uses machine learning to learn classification parameters and then applies those parameters deterministically to produce outputs satisfies Mandatory Property 1. A system that uses those parameters to generate outputs through probabilistic sampling does not.
9.3 Mandatory Property 2: Derivation Traceability
A financial AI system must produce, as an integral component of every output admitted into a financial data system, a complete and auditable record of the derivation of that output from primary source evidence. This derivation record must satisfy three conditions.
First, it must be produced simultaneously with the output, not reconstructed after the fact. Retrospective documentation of a derivation that was not recorded at the time of processing does not satisfy this requirement, because the derivation record must reflect the actual computational steps that produced the output rather than a post-hoc rationalisation of the result.
Second, it must be traceable to primary source evidence. The derivation chain must connect the output to the original source documents, bank records, invoices, contracts, or equivalent primary evidence from which the financial record was derived. A derivation chain that terminates at an intermediate data store rather than at primary source evidence does not satisfy this requirement.
Third, it must be independently verifiable. A third party with access to the primary source evidence and the derivation record must be able to reconstruct the output by following the derivation steps without access to the system that originally produced it. A derivation record that can only be interpreted with the assistance of the system that produced it provides insufficient audit verifiability.
This property directly addresses property P2 of the Stochastic Contamination Theorem and satisfies FEI property (iii). It is the property that most completely distinguishes FEI-compliant financial AI from both probabilistic AI systems and legacy manual processing. It requires that the system treat the derivation record as part of the financial record itself, not as optional supporting documentation.
9.4 Mandatory Property 3: Conservation Guarantee
A financial AI system must preserve the accounting conservation constraint as an invariant across every processing step. The system must be architecturally constructed such that no output can be admitted into the accepted financial state in a configuration that violates the conservation constraint. Conservation verification must be a structural property of the processing architecture, not a post-hoc check applied to outputs after generation.
This property satisfies FEI property (i) and eliminates the conservation propagation risk identified in Section 2.1. A system that checks conservation after generating outputs can produce a non-conserving output and detect it only after it has been generated, requiring a correction process that may itself introduce further outputs. A system that guarantees conservation by construction cannot generate a non-conserving output: the architecture prevents it from entering the accepted financial state.
The practical implementation of this property requires that the classification rules governing the system’s outputs be designed with conservation as a constraint embedded in every rule rather than as a global check applied after rules are executed. This is an architectural requirement on rule design, not merely on output verification.
9.5 Conditional Property 1: Enhanced Derivation Standard for Material Transactions
For transactions whose monetary impact exceeds a defined materiality threshold, the derivation traceability requirement is enhanced. The derivation record for a material transaction must include not only the rule applied and the source evidence from which the classification was derived, but also the specific characteristics of the source evidence that triggered the rule, the confidence assessment applied to the classification, and, where multiple plausible classifications existed, the basis on which alternative classifications were excluded.
This enhanced standard reflects the FEI legal obligation property’s requirement of demonstrable correctness. For material transactions, demonstrability requires not only that a derivation chain exists but that the derivation chain is sufficiently detailed to allow an auditor to assess whether the classification was appropriate given the specific characteristics of the evidence available. A derivation record that records only the rule applied and the output produced does not satisfy this requirement for material transactions: it records what happened but not why it was the correct thing to happen.
9.6 Conditional Property 2: Systemic Integration Reporting for Large-Scale Deployments
For AI systems processing financial data at scale, defined as systems processing financial records for more than a defined threshold number of entities or generating more than a defined threshold volume of financial records per period, an additional reporting requirement applies. The operator of such a system must produce, at intervals specified by the relevant regulatory authority, a statistical report on system performance against the FEI condition, including aggregate exception rates, classification confidence distributions, rule audit results, and any systematic deviations from expected processing patterns detected during the reporting period.
This requirement addresses the accumulation dynamic identified in Section 7.7. Individual entity-level audit cannot detect systemic contamination patterns that emerge only at aggregate scale. Systemic integration reporting requires that large-scale financial AI operators actively monitor for the emergence of such patterns and report them to regulators before they become embedded in financial data at systemic scale. It transforms the regulatory relationship from one of retrospective compliance checking to one of continuous systemic monitoring proportionate to the scale of the system’s financial data footprint.
9.7 The Fitness Standard and the Regulatory Frameworks
The Financial AI Fitness Standard proposed in this section is designed to interface directly with the regulatory gap analysis in Section 6. Each of the six frameworks examined in that section can incorporate the standard through a targeted amendment rather than a wholesale revision.
For the FRC, the standard provides the specific content for the auditable derivation requirement proposed in Section 6.1: AI systems used in audit engagements must satisfy Mandatory Properties 1, 2, and 3, and any AI-generated audit evidence must be accompanied by a derivation record satisfying Mandatory Property 2.
For the FCA, the standard provides the architectural minimum for the model risk management amendment proposed in Section 6.2: AI systems generating financial records in FCA-regulated firms must satisfy all three mandatory properties, with Conditional Property 1 applying to material transactions and Conditional Property 2 applying to large-scale deployments.
For the IAASB and PCAOB, the standard provides the content for the ISA 500 amendment proposed in Sections 6.3 and 6.4: AI-generated audit evidence is appropriate within the meaning of the standard only if it was produced by a system satisfying the Financial AI Fitness Standard, and in particular only if it is accompanied by a derivation record satisfying Mandatory Property 2.
For HMRC, the standard provides the architectural specification for the MTD software requirement proposed in Section 6.5: MTD-compatible software incorporating AI components must satisfy all three mandatory properties, and AI components not satisfying these properties are prohibited from generating financial records admitted directly into MTD submissions.
For Companies House, the standard provides the basis for the disclosure requirement proposed in Section 6.6: accounts generated using AI systems must include a statement confirming compliance with the Financial AI Fitness Standard, or where compliance cannot be confirmed, a disclosure that probabilistic AI was used in the generation of the accounts.
9.8 What the Standard Does Not Require
The Financial AI Fitness Standard does not prohibit AI in financial data processing. It prohibits a specific class of AI, probabilistic generative systems, from generating financial records admitted directly into financial data systems. It permits, and indeed encourages, the use of deterministic rule-based AI systems that satisfy the mandatory properties. Such systems can process financial data at scale, with superior efficiency and accuracy compared to manual processing, while maintaining the audit trail condition and conservation guarantee that the FEI condition requires.
The standard does not prohibit LLMs from all financial services applications. LLMs can provide value in financial contexts that do not involve generating financial records admitted into financial data systems: drafting client communications, summarising regulatory guidance, answering employee queries, analysing market commentary, and supporting advisory conversations. The prohibition is specific to the generation of financial records and the processing of financial data in ways that produce outputs admitted into the accepted financial state. Outside that boundary, the standard is silent.
The standard does not require that existing financial AI deployments be immediately replaced. It proposes a prospective requirement that systems deployed after the standard’s adoption satisfy the mandatory properties, with a transition period during which existing deployments are assessed for compliance and either brought into compliance or decommissioned. The transition period should be proportionate to the systemic risk assessment: high-volume deployments generating financial records for large numbers of entities warrant shorter transition periods than small-scale deployments with limited systemic footprint.
9.9 The Standard as a Foundation for Trust
The Financial AI Fitness Standard is ultimately a statement about what financial data is for. Financial data exists to represent economic reality accurately, verifiably, and consistently enough to support the legal, commercial, and policy decisions that depend on it. An AI system that cannot guarantee the accuracy of its outputs, cannot demonstrate the derivation of its outputs from source evidence, and cannot preserve the conservation constraints that financial data must satisfy is not a financial data processing system in any meaningful sense. It is a text generation system operating in a financial context, and the financial records it produces are not financial records in the FEI sense. They are plausible representations of financial records that may or may not correspond to the underlying economic reality.
The Financial AI Fitness Standard restores the correspondence between financial records and economic reality as a requirement rather than an aspiration. It does so not by mandating specific technologies or prohibiting innovation, but by requiring that whatever systems process financial data must be capable of doing what financial data processing requires: producing outputs that are deterministic, derivation-traceable, and conservation-preserving by architectural construction rather than by probabilistic approximation.
The financial system has operated for five centuries on the assumption that the data describing it can be trusted. That assumption is not self-maintaining. It requires that the systems generating financial data be architecturally capable of producing trustworthy outputs. The Financial AI Fitness Standard is the minimum specification for that architectural capability in the era of AI-assisted financial data processing. It is overdue.
9.10 A Carve-Out: Professional Estimation Under Missing Records Protocols
The Financial AI Fitness Standard as specified in Sections 9.2 through 9.6 requires deterministic output generation, derivation traceability to primary source evidence, and conservation guarantee as mandatory architectural properties. A careful reader will identify a category of established accounting practice that appears to challenge, or at minimum to complicate, the mandatory derivation traceability requirement: professional estimation under missing records protocols, a recognised and legally accepted practice in which a qualified accountant prepares financial records using estimation, averaging, benchmarking, or reconstruction techniques where primary source evidence is unavailable or incomplete.
This section clarifies the relationship between professional estimation and the FEI condition, establishes the basis on which such estimation is conditionally FEI-compatible, and identifies the conditions under which it is not, with direct implications for the Financial AI Fitness Standard.
The nature of professional estimation under missing records
Where a business has incomplete or missing financial records, qualified accountants are permitted by professional standards and accepted by HMRC to prepare accounts on an estimated basis, provided the estimation is conducted in accordance with defined professional protocols. HMRC’s own guidance acknowledges this practice: where records are incomplete, the taxpayer and their agent may use reasonable estimation methods, including extrapolation from available records, industry benchmarking, and reconstruction from secondary evidence such as bank statements, supplier records, and VAT returns, to arrive at figures that represent a reasonable approximation of the underlying financial reality (HMRC Enquiry Manual, EM2759). The resulting accounts are submitted with appropriate disclosure that they are prepared on an incomplete records basis, and HMRC retains the power to challenge the reasonableness of the estimation methodology applied.
This practice is not a failure of financial data integrity. It is a formally recognised mechanism for producing the best available approximation of financial truth in circumstances where complete source derivation is impossible. It has its own epistemology: the accounts are not claimed to be derivation-traceable to primary source evidence in the full FEI sense. They are claimed to be the product of a defined, documented, and professionally governed estimation methodology applied to the best available evidence, with explicit disclosure of their estimated nature.
The FEI status of professionally estimated accounts: a context-dependent analysis
Professional estimation under missing records protocols is FEI-compatible where three conditions are jointly satisfied, and FEI-incompatible where any of them is absent.
The first condition is protocol formality. The estimation methodology must be formally defined before it is applied, not constructed post hoc to justify a desired outcome. A methodology that specifies in advance the sources of secondary evidence to be used, the benchmarking approach to be applied, the materiality threshold governing the precision required, and the basis on which the results will be documented satisfies this condition. A methodology that emerges discretionarily from the professional’s judgment during the estimation process, without prior formal specification, does not.
The second condition is derivation traceability of the methodology itself. Where primary source evidence for individual transactions is unavailable, the FEI derivation traceability requirement applies to the estimation methodology rather than to each individual figure. The methodology must be traceable: the auditor or regulator examining the estimated accounts must be able to follow the chain of reasoning from the available secondary evidence through the estimation method to the resulting figures, and must be able to assess whether the methodology was appropriately applied. An estimation methodology that is not documented in sufficient detail to permit this assessment fails the audit verifiability property, even if the resulting figures are reasonable.
The third condition is explicit disclosure. Estimated accounts must be identified as such, with the estimation methodology disclosed in sufficient detail to allow the reader to assess its basis. This disclosure is required both by professional standards and by HMRC practice, which expects agents to indicate when accounts have been prepared on an incomplete records basis and to describe the methods used. The disclosure transforms the epistemic status of the figures from claimed primary-source-derived truth to acknowledged estimated approximation, which is a different but legitimate category of financial representation.
Where all three conditions are satisfied, professionally estimated accounts occupy a recognised and legally accepted epistemic category distinct from both full FEI compliance and Stochastic Contamination. They are not fully FEI-compliant in the strict sense: the derivation chain terminates at the estimation methodology rather than at primary source evidence for each figure. But they are not contaminated in the sense defined in Section 3: the uncertainty introduced by the estimation is explicitly represented in the accounts, disclosed to the user, and auditable through the documented methodology. The contamination definition requires that probabilistic uncertainty be unrepresented in the audit trail. A disclosed, documented estimation methodology is, by definition, represented.
The critical distinction from Stochastic Contamination
The distinction between professional estimation under missing records protocols and Stochastic Contamination is not a matter of degree. It is a matter of epistemic category.
Professional estimation introduces acknowledged uncertainty into financial records with explicit disclosure, documented methodology, and professional accountability. The uncertainty is visible. The methodology that produced it is auditable. The professional who applied it is identifiable and accountable. The regulatory framework specifically provides for this category of financial representation through HMRC’s acceptance of incomplete records submissions and the accounting profession’s documented methodology for their preparation.
Stochastic Contamination introduces unacknowledged uncertainty into financial records without disclosure, without an auditable methodology, and without a traceable derivation from either primary source evidence or a formally specified estimation protocol. The uncertainty is invisible. The process that produced it cannot be inspected. The system that generated the contaminated output carries no accountability in the professional or regulatory sense. No regulatory framework provides for this category, because no regulatory framework has yet conceptualised it.
The Financial AI Fitness Standard is therefore not in tension with the existing practice of professional estimation under missing records protocols. It prohibits Stochastic Contamination, not acknowledged estimation. A system that applies a formally specified, documented estimation methodology to available secondary evidence, produces outputs whose derivation from that methodology is traceable, and discloses the estimated nature of its outputs satisfies the spirit of the mandatory properties, because it satisfies the underlying FEI requirement that uncertainty in financial records be explicit, documented, and auditable rather than hidden, undocumented, and invisible.
Implications for the Financial AI Fitness Standard
The analysis above gives rise to a fourth conditional property of the Financial AI Fitness Standard, applicable specifically to AI systems operating in incomplete records contexts.
Conditional Property 3: Estimation Protocol Compliance for Incomplete Records Contexts. An AI system operating on financial data in a context where primary source evidence is unavailable or incomplete may produce outputs based on formally specified estimation protocols, provided that the estimation methodology is defined before application, its application to the available secondary evidence is derivation-traceable in accordance with Mandatory Property 2 as applied to the methodology rather than to primary sources, and every output produced by the estimation process is explicitly identified as an estimated figure with the methodology disclosed in the accompanying documentation.
An AI system that generates estimated financial figures through a probabilistic process rather than through a formally specified estimation methodology does not satisfy Conditional Property 3. The distinction is architectural: a deterministic system applying a formal estimation protocol produces outputs that are traceable to the protocol and auditable through it. A probabilistic system generating plausible estimated figures produces outputs that are traceable only to a probability distribution, which is not a formally specified estimation protocol and cannot serve the same epistemic and accountability functions.
The carve-out for professional estimation under missing records protocols therefore, confirms rather than weakens the central argument of this paper. The accounting profession has, over centuries of practice, developed a recognised category for situations where full derivation traceability is impossible. That category is characterised by explicit disclosure, formal methodology, and professional accountability. It is precisely the opposite of Stochastic Contamination in every respect that matters. Its existence demonstrates that the financial system knows how to handle uncertainty in financial data: by making it visible, documented, and auditable. What the Financial AI Fitness Standard requires is that AI systems operating on financial data do the same.
10. Conclusion
The deployment of probabilistic AI in financial data processing is not merely a governance challenge requiring better oversight, but is a category error requiring architectural correction. The Financial Epistemic Integrity condition is, therefore, not a nice-to-have, but a formal property of financial data whose three components, mathematical conservation, legal demonstrability, and audit verifiability, jointly constitute what financial data must be in order to function as financial data. The Stochastic Contamination Theorem is a proof that probabilistic AI systems violate that property by architectural necessity, regardless of their capability, their calibration, or the governance arrangements surrounding their deployment.
The significance of this distinction cannot be overstated. A risk can be managed. An architectural incompatibility cannot. Every mitigation strategy the industry has proposed for LLM deployment in financial contexts, retrieval augmentation, domain fine-tuning, constitutional constraints, human oversight, addresses the probability of incorrect outputs. None addresses the absence of derivation traceability that makes every output from a probabilistic system a contaminated financial record regardless of whether it happens to be numerically correct. The contamination is not in the number. It is in the absence of proof that the number is right.
What this paper has introduced, and what it asks the academic and regulatory communities to engage with seriously, is a new theoretical object: the concept of financial data as a verified epistemic category with formal properties that constrain the class of systems permitted to generate it. This is not a concept that exists in the current literature on AI governance, financial regulation, or accounting theory. Its absence is the gap through which probabilistic AI is currently flowing into financial data systems across the economy, contaminating records that are then audited, filed, submitted to tax authorities, published as the basis for investment decisions, and aggregated into the national statistics on which macroeconomic policy depends.
The accumulation dynamic described in Section 7.7 is the most urgent dimension of the problem. Contamination at the transaction level is invisible. Contamination at the audit level is invisible. Contamination at the market level is invisible until it is not, at which point the irrecoverability property ensures that the damage is already permanent. The financial system has no early warning mechanism for Stochastic Contamination because the concept does not yet exist in the frameworks through which the financial system monitors its own integrity. This paper creates that concept. The regulatory and standard-setting community now has a choice about whether to act on it.
The Financial AI Fitness Standard proposed in Section 9 is the minimum architectural specification that makes that choice concrete. It is not the end of the conversation about AI in finance. It is the beginning of a conversation conducted on the correct terms: not how to govern probabilistic AI in financial contexts, but whether the architectural properties of probabilistic AI are compatible with the epistemic requirements of financial data, and what class of system must be used instead when they are not.
The answer this paper provides is precise, formal, and empirically grounded.
Probabilistic AI systems are not financially fit. The standard for what fitness requires has been defined. The question that remains is now outside of the intellectual realm and has become institutional.
© Lucy Cohen. This work is licensed under Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0).
You are free to share this work with attribution for non-commercial purposes. No adaptations or derivative works permitted without written permission.

Lucy Cohen MBA, FMAAT
Inventor, disruptor and researcher at the intersection of accountancy and artificial intelligence. Founder of the UK’s subscription accountancy model and the driving force behind the UK’s most successful female-founded accountancy business – Mazuma, a multi-million-pound firm serving thousands of micro-businesses and sole traders. A practitioner who doesn’t just observe the future of the profession: she shapes it.
Creator of a novel accounting principle architected for delivery through AI – the subject of several papers currently in publication and the foundation of a doctoral research programme. A respected author, researcher and national media commentator on financial AI, whose work is reshaping how the profession thinks about automation, intelligence and the role of the accountant.
President of the Association of Accounting Technicians 2025-26 (AAT), representing 130,000+ members and students across 105+ countries. Policy adviser to Number 10 Downing Street and the Small Business Commissioner on late payments legislation. Regular contributor to BBC, Sky News, ITV and Forbes.
References
Audit Analytics (2023). Financial Restatements: A Sixteen Year Comparison. Audit Analytics Annual Report. Ives Group.
Barchard, K.A., Freeman, S., Ochoa, C.Y. and Stephens, J.A. (2020). “Comparing the accuracy of individuals and teams in data entry.” Behavior Research Methods, 52(6), 2615–2628.
Cohen, L. (2024). Accounting by Exception: A New Framework for Transaction Management in Micro Businesses. Unpublished manuscript. Mazuma GB Limited.
Companies House (2025). Annual Report and Accounts 2024 to 2025. HM Government. Available at: https://www.gov.uk/government/publications/companies-house-annual-report-and-accounts-2024-to-2025
Economic Crime and Corporate Transparency Act 2023. UK Public General Acts 2023 c.56.
Financial Conduct Authority (2024). AI Update: FCA’s Approach to Artificial Intelligence. April 2024. Available at:
https://www.fca.org.uk
Financial Conduct Authority (2025). AI Sprint: Summary of Feedback. April 2025. Available at:
https://www.fca.org.uk
Financial Reporting Council (2024). Key Facts and Trends in the Accountancy Profession. FRC Annual Report 2023–24. Available at:
https://www.frc.org.uk
Financial Reporting Council (2026). Guidance for Audit Firms on Using Generative and Agentic AI Tools in Audit Engagements. March 2026. Available at:
https://www.frc.org.uk
Gekhman, Z., Yona, G., Aharoni, R., Eyal, M., Feder, A., Reichart, R. and Herzig, J. (2024). “Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?” In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7765–7784. Miami, Florida: Association for Computational Linguistics. arXiv:2405.05904.
HMRC (2019). Understanding the Causes of the Tax Gap: Small Business. HM Revenue and Customs Research Report 543.
HMRC (2025a). Measuring Tax Gaps 2025 Edition. HM Revenue and Customs. Available at: https://www.gov.uk/government/statistics/measuring-tax-gaps
HMRC (2025b). HMRC Transformation Roadmap. July 2025. Available at: https://www.gov.uk/government/publications/hmrc-transformation-roadmap
IAASB (2023). International Standards on Auditing: 2023 Handbook. International Auditing and Assurance Standards Board. New York: IFAC.
IAASB (2024). Technology Position Paper: Exploring the Use of Technology in Audit. International Auditing and Assurance Standards Board. Available at:
https://www.iaasb.org
Kang, H. and Liu, X-Y. (2023). “Deficiency of Large Language Models in Finance: An Empirical Examination of Hallucination.” arXiv:2311.15548.
Kleinberg, J. and Mullainathan, S. (2024). “Language Generation in the Limit.” In Advances in Neural Information Processing Systems, Volume 37 (NeurIPS 2024). Curran Associates. arXiv:2404.06757.
Moloi, T. and Obeid, H. (2024). “Enablers, barriers and strategies for adopting new technology in accounting.” Journal of International Accounting, Auditing and Taxation, 54, 100583.
Panko, R.R. (1998). “What we know about spreadsheet errors.” Journal of End User Computing, 10(2), 15–21.
Pyzdek, T. and Keller, P. (2014). The Six Sigma Handbook, 4th edition. New York: McGraw-Hill.
Sun, Z., Zang, X., Zheng, K., Song, Y., Xu, J., Zhang, X., Yu, W., Song, Y. and Li, H. (2025). “ReDeEP: Detecting Hallucination in Retrieval-Augmented Generation via Mechanistic Interpretability.” ICLR 2025 Spotlight. arXiv:2410.11414.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L. and Polosukhin, I. (2017). “Attention Is All You Need.” Advances in Neural Information Processing Systems, 30. arXiv:1706.03762.
Zhang, W. et al. (2025). “Hallucination Mitigation for Retrieval-Augmented Large Language Models: A Review.” Mathematics, 13(5), 856. DOI: 10.3390/math13050856.